17. CNN¶
Convolutional Neural Networks(CNN)은 convolution 레이어를 사용하는 신경망 구조입니다. 컴퓨터 비전에서 이미지 데이터에 일반적으로 사용합니다. CNN은 이미지를 분류하는 image classification, 객체의 위치를 탐지하는 object detection, 이미지 내 각 픽셀이 나타내는 객체를 탐지하는 segmentation, 그리고 이미지를 생성하는 image generation에서 주로 사용되는 모델입니다.

그림 17-1 Image classification 예시(출처)

그림 17-2 Object detection 예시(출처)

그림 17-3 Segmentation 예시(출처)

그림 17-4 Image generation 예시(출처)
17.1 Convolution¶
Convolution 연산은 두 개의 함수를 조합하는 연산입니다. 그림 17-5와 그림 17-6에는 1차원 convolution 연산을 보여주고 있습니다. 파란색 선은 f함수를 나타내며 빨간색 선은 g함수를 나타냅니다. 그리고 빨간색 선이 파란색 선을 지날 때 두 개의 함수간 연산이 진행되며 이 과정에서 convolution 연산의 결과물인 검은색 선이 생성됩니다.
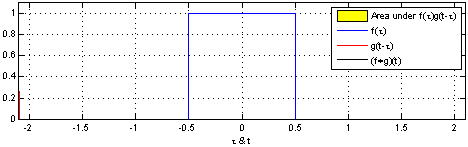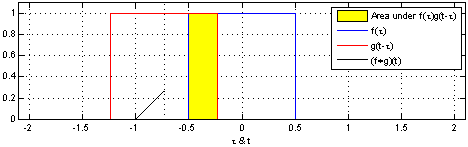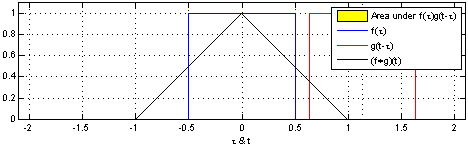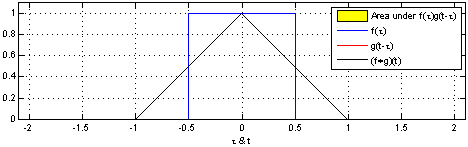
그림 17-5 convolution 연산 예시 1(출처)

그림 17-6 convolution 연산 예시 2(출처)
그림 17-7에서는 2차원 convolution 연산을 보여주고 있습니다. 초록색 사각형이 f함수이며 주황색 사각형이 g함수라고 볼 수 있습니다. 주황색 사각형을 필터라고도 하는데 필터가 지나갈 때 마다 내적 연산이 이뤄져서 분홍색 사각형의 결과물이 산출됩니다.

그림 17-7 convolution 연산 예시 3(출처)
신경망 모델의 1차원 Fully Connected(FC) 레이어와 비교했을 때 2차원 convolution 레이어는 이미지의 위치 정보를 보존하는 장점이 있습니다. 1차원 레이어에 이미지를 입력값으로 주기 위해선 이미지를 1차원으로 펼치는 과정이 필요합니다. 이 과정에서 위치 정보 손실이 일어납니다. 하지만 2차원 convolution 레이어에는 이미지 데이터를 변환 없이 입력할 수 있기 때문에 위치 정보가 보존됩니다.
또한 2차원 convolution 레이어를 사용하면 FC 레이어 보다 학습해야 하는 가중치의 개수가 적습니다. FC 레이어를 사용하면 그림 17-7 예시에서 5 x 5 x 3 x 3 = 225개의 가중치를 학습해야 합니다. 하지만 2차원 convolution 레이어를 사용하면 필터에 있는 9개의 가중치만 학습을 해주면 됩니다.
Convolution 레이어를 사용할 때 추가적으로 적용가능한 여러 옵션들이 존재합니다. Padding은 입력 가장자리에 0을 추가해서 원본 이미지의 가장자리 정보가 여러번 연산에 활용될 수 있도록 합니다. Striding은 필터가 건너뛰는 단위를 뜻합니다. 1보다 큰 숫자를 설정하면 출력되는 차원이 축소되는 효과를 지닙니다. Pooling은 일정 영역의 평균값/최댓값을 선택해서 반환하는 연산이며 차원 축소 효과를 지닙니다. Convolution 연산이 끝난 후에는 Flattening을 통해 1차원으로 변경해서 이미지 분류나 기타 작업을 진행합니다.
CNN Explainer에서 CNN 연산이 적용되는 과정을 상세하게 확인해 볼 수 있습니다. 또한 3D Visualization of a Convolutional Neural Network 웹사이트에서 CNN이 적용되는 과정을 3D 그래픽으로 확인할 수 있습니다.
17.2 유명한 CNN - Classification¶
아래 표에는 이미지 분류에 적용되는 주요 CNN 구조들이 요약돼 있습니다.
신경망 구조 |
설명 |
|---|---|
LeNet (Yann LeCun, 1998) |
7 레이어. ATM 손글씨 인식에 사용. CNN의 첫 번째 성공사례 |
AlexNet (Alex Krizhevsky, 2012) |
8 레이어. 60MM 변수. ImageNet 대회 우승 (ER: 16.4%). GPU를 사용한 첫 사례. |
GoogleNet (aka Inception v1, 2014) |
22 레이어. 6.8MM 변수. ImageNet 1위 (ER: 6.7%). |
VGGNet (K. Simonyan & A. Zisserman, 2014) |
16 레이어. 138MM 변수. ImageNet 2위 (ER: 7.3%). |
ResNet (Kaiming He et al., 2015) |
152 레이어. 23MM 변수. ImageNet 1위 (ER: 3.57%) |
ResNeXt (Kaiming He, 2016) |
ImageNet 2위. ER: 3.03% |
SENets (Jie Hu et al., 2017) |
ImageNet 1위. ER: 2.25% |
MobileNet (Google, 2017) |
0.5~4.2MM 변수. ER: 7.9% |
EfficientNet (Google, 2020) |
ER: 2.9% |
표 17-1 주요 CNN 구조 - Classification
17.3 유명한 CNN - Segmentation / Detection¶
아래 표에는 Segmentation / Detection에 적용되는 주요 CNN 구조들이 요약돼 있습니다.
신경망 구조 |
설명 |
|---|---|
U-Net (U of Freiburg, 2015) |
Segmentation |
Faster R-CNN (Kaiming He, et al., 2016) |
Detection |
Mask R-CNN (Kaiming He, et al., 2017) |
Faster R-CNN (detection) + FCN (segmentation) |
표 17-2 주요 CNN 구조 - Segmentation / Detection

그림 17-8 U-Net 구조(출처)

그림 17-9 Mask R-CNN 결과물 예시(출처)
17.4 참고자료¶
Lecture 5: Convolutional Neural Networks at Stanford CS231n 2018
Stanford의 CS231n은 컴퓨터 비전을 다루는 한 학기 분량의 강의입니다.
아래는 주요 컴퓨터 비전 캐글 대회입니다.