13. 문자열변수 가공¶
이번 장에서는 문자열변수 가공에 대해 살펴보겠습니다.
13.1 문자열¶
문자열은 문자 메시지, 상품 리뷰, 문서 등 일상에서 쉽게 접할 수 있는 데이터 형태입니다. 문자열을 처리 하는 학문을 Natural Language Processing(NLP; 자연어처리) 라고 합니다. NLP는 언어학/전산학/AI가 결합된 융합 학문입니다. 약 1950년대부터 연구가 진행됐으며 최근 들어서는 딥러닝의 진보로 인해 전성기를 맡게된 학문 중 하나입니다. 기계번역, 스팸분류, 감정분류, 중복검사, 챗봇, 작문평가 등 다양한 분야에서 활용됩니다.
13.2 문자열 전처리¶
문자열 데이터를 머신러닝 알고리즘에 적용하기 위해선 숫자로 먼저 변경해줘야 합니다. 문자열을 수치화 하기 위해선 대문자를 소문자로 통일하거나 문장부호는 제거하는 등 일련의 전처리 과정을 겪게 됩니다. 문자열 전처리시 유용하게 사용 가능한 도구들에 대해 살펴보겠습니다.
13.2.1 파이썬 문자열 빌트인 함수¶
가장 먼저 파이썬의 문자열 데이터 형태가 자체적으로 제공하는 함수를 사용할 수 있습니다.
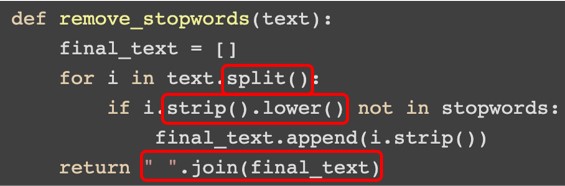
그림 13-1 빌트인 함수 예제(출처)
그림 13-1에 있는 빨간색 박스 내의 함수가 파이썬의 빌트인 함수입니다. split()은 공백 기준으로 문자열을 나눠주며 strip()은 양 옆의 공백을 제거해줍니다. lower()은 모든 문자를 소문자로 변환하는 함수이며 join()은 분할된 단어들을 하나의 문자열로 결합하는 함수입니다.
13.2.2 파이썬 정규식 라이브러리 - re¶
파이썬에서 제공하는 정규식(regular expression) 라이브러리인 re를 활용해서 문자열 처리도 가능합니다.

그림 13-2 re 사용 예제(출처)
위 예시에서 [^A-Za-z0-9]식은 영어와 숫자를 제외한 모든 문자를 뜻합니다. 그래서 re에서 제공하는 sub()함수를 통해 영어와 숫자가 아닌 모든 문자를 ''로 변환하는 식입니다. 정규식에 대한 세부 설명은 파이썬 공식 문서에서 확인 가능합니다.
13.2.3 Pandas str 함수¶
Pandas의 데이터프레임 내에 특정 열이 문자열로만 이뤄져있다면 Pandas의 str 문법을 통해 문자열 처리가 가능합니다.

그림 13-3 Pandas str 사용 예제(출처)
그림 13-3처럼 s2에 문자열인 series가 저장돼있을 시 str.split('_')함수를 통해 _기준으로 문자열을 나눌 수 있습니다. 나눈 결과에서 특정 위치에 있는 원소를 추출할 때는 str.get()을 사용할 수 있습니다. 위 예시에서는 리스트에서 1번째 위치에 있는 문자를 추출했습니다.
13.2.4 자연어 라이브러리¶
이 외에도 NLTK나 spaCy같은 자연어 라이브러리를 통해 문자열 처리가 가능합니다. NLTK와 spaCy가 자연어 라이브러리 중 가장 대표적인 라이브러리입니다.
NLTK의 유용한 기능으로 언어별 불용어 사전을 제공합니다. 불용어는 a, the 처럼 빈번히 등장하는 단어를 뜻하며 제거를 하면 자연어 처리시 더 좋은 성능을 보일 수 있습니다.

그림 13-4 NLTK에서 제공하는 영어 불용어 사전(출처)
이 외에도 NLTK에서 유용하게 사용되는 기능으로 Tokenizer, Stemming, 그리고 Lemmatization이 있습니다. Tokenizer은 하나의 문장을 단어와 문장부호로 나눠주는 역할을 합니다.

그림 13-5 Tokenizer, Stemming, Lemmatization(출처)

그림 13-6 Tokenizer 사용 예제(출처)
Lemmatization은 단어의 기본형을 찾아주는 과정입니다. 영어는 특정 단어가 상황에 따라 여러 형태를 지닐 수 있습니다. 예를 들어 gentleman이 복수 형태로 쓰일 때는 gentlemen으로 사용됩니다. 이처럼 다양한 형태의 단어를 기본형으로 바꿔주는 작업을 lemmatization이라고 합니다.
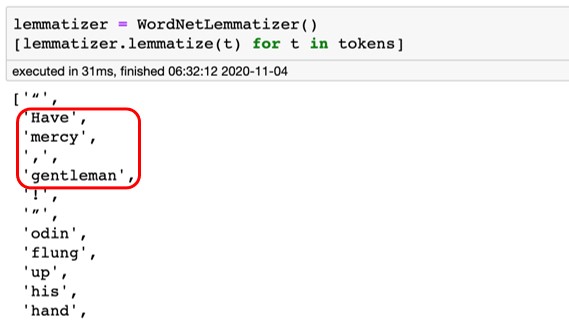
그림 13-7 Lemmatization 사용 예제(출처)
Lemmatization은 언어학적인 관점으로 기본형을 찾는다면 stemming은 기본적인 규칙 몇가지 만으로 단어를 통일하는 과정입니다.
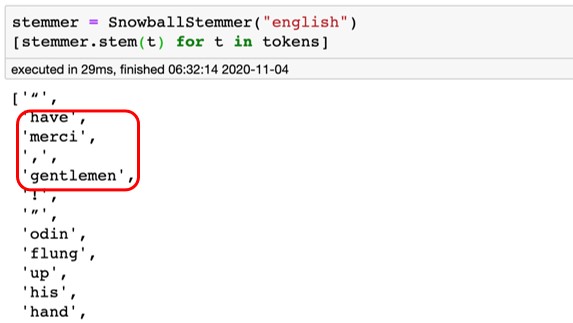
그림 13-8 Stemming 사용 예제(출처)
Tip
일반적으로 lemmatization은 언어학적인 관점으로 다양한 규칙을 적용하기 때문에 처리 시 stemming보다 시간이 오래 걸립니다. Lemmatization과 stemming를 사용했을 때 최종 모델 성능은 일반적으로 비슷하게 나오므로 속도가 빠른 stemming을 데이터과학 대회에서는 선호하는 편입니다.
spaCy에서는 전처리 기능 뿐만 아니라 문자열을 가공하는 여러 기능을 제공합니다. 하지만 최근에는 문자열 가공시 신경망을 사용한 방법을 주로 사용하기 때문에 spaCy보다는 Keras나 PyTorch로 가공을 진행하는 편입니다.
13.3 문자열 가공¶
전처리된 문자열을 모델 학습시 사용 가능한 피쳐로 가공하는 방식에 대해 살펴보겠습니다. 과거에는 Bag-of-Words와 Hashing Trick이 사용됐으며 최근에는 Embedding 기법이 주로 사용됩니다.
13.3.1 Bag-of-Words¶
Bag-of-Words 방식은 크게 CountVectorizer와 TfidfVectorizer 방법으로 나뉩니다.
CountVectorizer는 각 단어의 빈도를 피쳐로 사용하는 방법입니다. 예를 들어 한 문장을 피쳐로 변환할 때 해당 문장 내 have가 2번 등장하면 have범주에 해당하는 위치에 2를 적어주는 방식입니다.

그림 13-9 CountVectorizer 사용 예제(출처)
그림 13-9는 sklearn.feature_extraction.text모듈에서 제공하는 CountVectorizer()함수 사용 예제 입니다. tokenizer와 stop_words파라미터에 각각 NLTK에서 제공하는 tokenizer와 stopwords 사전을 입력하면 해당 기능을 활용해 토큰화를 한 뒤 불용어는 제거하고 남은 토큰들에 대해서 CountVectorizer를 적용하게 됩니다. min_df와 max_features파라미터를 활용해 피쳐의 개수를 제한할 수 있습니다. min_df에 50을 입력하면 전체 텍스트에서 50번 이상 등장하는 단어들만 피쳐로 활용한다는 뜻이며 max_features는 최대 피쳐의 개수를 제한시켜주는 파라미터입니다.
TfidfVectorizer는 각 단어의 빈도를 역문서 빈도로 나눈 값을 피쳐로 사용하는 방법입니다. 단어의 빈도를 역문서 빈도로 나눠줌으로써 다른 문서에도 빈번히 등장하는 단어들의 가중치는 낮추고 특정 문서에서만 자주 등장하는 단어들의 가중치는 높여주는 효과를 부여합니다.

그림 13-10 TfidfVectorizer 사용 예제(출처)
그림 13-10 은 sklearn.feature_extraction.text모듈에서 제공하는 TfidfVectorizer()함수 사용 예징니다. CountVectorizer()와 입력받는 파라미터가 유사합니다.
Tip
CountVectorizer()의 출력값은 멱함수 분포를 가지기 때문에 로지스틱회귀나 신경망 모델에 입력시 정규화를 해줘야 합니다. 하지만 TfidfVectorizer()의 출력값은 idf에 의해 어느정도 정규화가 이뤄지기 때문에 로지스틱회귀나 신경망 모델의 입력값으로 즉시 사용 가능합니다.
Note
CountVectorizer()와 TfidfVectorize()를 통해 반환되는 값의 데이터 형태는 scipy.sparse.csr_matrix 입니다. 해당 형태는 scikit-learn, lightgbm, xgboost 라이브러리에서 제공하는 머신러닝 알고리즘에는 입력값으로 사용 가능합니다. 하지만 Keras나 PyTorch로 만든 신경망 모델에 입력값으로 사용하기 위해선 numpy의 dense matrix로 변환을 해줘야 합니다. todense()를 사용해 변환 가능합니다.
13.3.2 Hashing Trick¶
11.5.8절에서 문자열 변수에 hash 함수를 적용해 hash 값으로 변환하는 hashing trick에 대해 살펴봤습니다. 전처리가 끝난 텍스트 데이터에 대해서도 hash 함수를 적용해 hash 값으로 변환하는 방법을 적용할 수 있습니다.
13.3.3 Embeddings¶
이번 절에서는 embedding에 대한 간단한 개념을 살펴보고 자세한 내용과 실습은 14장에서 살펴보겠습니다.
Embedding은 ordinal/label encoding된 정수를 실수 벡터로 변환하는 과정입니다. 예를 들어 dog이란 단어를 2로 label encoding 한 후 [0.25, 1.00]의 실수 벡터로 변환하는 과정을 embedding이라고 합니다.
일반적으로 신경망을 활용해 embedding을 실시합니다. Embedding의 종류로는 Word2Vec, Glove, Elmo 등이 있으며 최근에는 BERT를 활용한 embedding을 사용하기도 합니다.
Embedding의 기본적인 개념은 embedding layer를 포한한 신경망 모델을 구축해서 학습 한 뒤 embedding layer에서 나온 출력값을 embedding 값으로 사용합니다.

그림 13-11 Embedding 도식화(출처)
신경망 구조에 따라 embedding의 종류가 달라집니다. 그림 13-12 의 왼쪽은 CBOW embedding을 생성하는 신경망 구조이며 오른쪽은 Skip-gram embedding을 생성하는 신경망 구조입니다.

그림 13-12 CBOW와 Skip-gram(출처)