데모¶
라이브러리 import 및 설정¶
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from lightgbm import LGBMClassifier
from matplotlib import pyplot as plt
from matplotlib import rcParams
import numpy as np
import optuna.integration.lightgbm as lgb
from pathlib import Path
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold, train_test_split
import seaborn as sns
import warnings
rcParams['figure.figsize'] = (16, 8)
plt.style.use('fivethirtyeight')
pd.set_option('max_columns', 100)
pd.set_option("display.precision", 4)
warnings.simplefilter('ignore')
학습데이터 로드¶
03-pandas-eda.ipynb에서 생성한 feature.csv 피처파일 사용
data_dir = Path('../data/dacon-dku')
feature_dir = Path('../build/feature')
val_dir = Path('../build/val')
tst_dir = Path('../build/tst')
sub_dir = Path('../build/sub')
trn_file = data_dir / 'train.csv'
tst_file = data_dir / 'test.csv'
sample_file = data_dir / 'sample_submission.csv'
target_col = 'class'
n_fold = 5
n_class = 3
seed = 42
algo_name = 'lgb_optuna'
feature_name = 'feature'
model_name = f'{algo_name}_{feature_name}'
feature_file = feature_dir / f'{feature_name}.csv'
p_val_file = val_dir / f'{model_name}.val.csv'
p_tst_file = tst_dir / f'{model_name}.tst.csv'
sub_file = sub_dir / f'{model_name}.csv'
df = pd.read_csv(feature_file, index_col=0)
print(df.shape)
df.head()
(400000, 20)
| z | redshift | dered_u | dered_g | dered_r | dered_i | dered_z | nObserve | airmass_u | class | d_dered_u | d_dered_g | d_dered_r | d_dered_i | d_dered_z | d_dered_ig | d_dered_zg | d_dered_rz | d_dered_iz | d_obs_det | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||||
| 0 | 16.9396 | -8.1086e-05 | 23.1243 | 20.2578 | 18.9551 | 17.6321 | 16.9089 | 2.9444 | 1.1898 | 0.0 | -0.1397 | -0.0790 | -0.0544 | -0.0403 | -0.0307 | -2.6257 | -3.3488 | 2.0462 | 0.7232 | -15.0556 |
| 1 | 13.1689 | 4.5061e-03 | 14.9664 | 14.0045 | 13.4114 | 13.2363 | 13.1347 | 0.6931 | 1.2533 | 1.0 | -0.0857 | -0.0574 | -0.0410 | -0.0322 | -0.0343 | -0.7683 | -0.8698 | 0.2767 | 0.1016 | -0.3069 |
| 2 | 15.3500 | 4.7198e-04 | 16.6076 | 15.6866 | 15.4400 | 15.3217 | 15.2961 | 1.0986 | 1.0225 | 0.0 | -0.1787 | -0.1388 | -0.0963 | -0.0718 | -0.0540 | -0.3649 | -0.3905 | 0.1440 | 0.0257 | -0.9014 |
| 3 | 19.6346 | 5.8143e-06 | 25.3536 | 20.9947 | 20.0873 | 19.7947 | 19.5552 | 1.6094 | 1.2054 | 0.0 | -0.3070 | -0.1941 | -0.1339 | -0.1003 | -0.0795 | -1.2000 | -1.4395 | 0.5321 | 0.2395 | -1.3906 |
| 4 | 17.9826 | -3.3247e-05 | 23.7714 | 20.4338 | 18.8630 | 18.1903 | 17.8759 | 2.6391 | 1.1939 | 0.0 | -0.6820 | -0.2653 | -0.1794 | -0.1339 | -0.1067 | -2.2436 | -2.5579 | 0.9871 | 0.3144 | -9.3609 |
y = df[target_col].values[:320000]
df.drop(target_col, axis=1, inplace=True)
trn = df.iloc[:320000].values
tst = df.iloc[320000:].values
feature_name = df.columns.tolist()
print(y.shape, trn.shape, tst.shape)
(320000,) (320000, 19) (80000, 19)
Hyperparameter Tuning¶
X_trn, X_val, y_trn, y_val = train_test_split(trn, y, test_size=.2, random_state=seed)
params = {
"objective": "multiclass",
"metric": "multi_logloss",
"num_class": 3,
"n_estimators": 1000,
"subsample_freq": 1,
"lambda_l1": 0.,
"lambda_l2": 0.,
"random_state": seed,
"n_jobs": -1,
}
dtrain = lgb.Dataset(X_trn, label=y_trn)
dval = lgb.Dataset(X_val, label=y_val)
model = lgb.train(params, dtrain, valid_sets=[dtrain, dval],
verbose_eval=100, early_stopping_rounds=10)
prediction = np.argmax(model.predict(X_val, num_iteration=model.best_iteration),
axis=1)
accuracy = accuracy_score(y_val, prediction)
params = model.params
print("Best params:", params)
print(" Accuracy = {}".format(accuracy))
print(" Params: ")
for key, value in params.items():
print(" {}: {}".format(key, value))
[I 2020-10-05 01:38:56,754] A new study created in memory with name: no-name-6a091e98-0e25-46bd-a749-ed1a9211b661
feature_fraction, val_score: inf: 0%| | 0/7 [00:00<?, ?it/s]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.162292 valid_1's multi_logloss: 0.173038
[200] training's multi_logloss: 0.147386 valid_1's multi_logloss: 0.166751
[300] training's multi_logloss: 0.138664 valid_1's multi_logloss: 0.165094
[400] training's multi_logloss: 0.131529 valid_1's multi_logloss: 0.164127
Early stopping, best iteration is:
[409] training's multi_logloss: 0.130959 valid_1's multi_logloss: 0.164059
feature_fraction, val_score: 0.164059: 14%|#4 | 1/7 [00:11<01:09, 11.58s/it][I 2020-10-05 01:39:08,337] Trial 0 finished with value: 0.16405917331427203 and parameters: {'feature_fraction': 0.7}. Best is trial 0 with value: 0.16405917331427203.
feature_fraction, val_score: 0.164059: 14%|#4 | 1/7 [00:11<01:09, 11.58s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.164111 valid_1's multi_logloss: 0.174182
[200] training's multi_logloss: 0.148453 valid_1's multi_logloss: 0.16733
[300] training's multi_logloss: 0.139438 valid_1's multi_logloss: 0.165289
[400] training's multi_logloss: 0.132501 valid_1's multi_logloss: 0.164311
[500] training's multi_logloss: 0.126573 valid_1's multi_logloss: 0.163827
Early stopping, best iteration is:
[492] training's multi_logloss: 0.127006 valid_1's multi_logloss: 0.163806
feature_fraction, val_score: 0.163806: 29%|##8 | 2/7 [00:25<01:01, 12.38s/it][I 2020-10-05 01:39:22,584] Trial 1 finished with value: 0.16380641954973035 and parameters: {'feature_fraction': 0.6}. Best is trial 1 with value: 0.16380641954973035.
feature_fraction, val_score: 0.163806: 29%|##8 | 2/7 [00:25<01:01, 12.38s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.16075 valid_1's multi_logloss: 0.17161
Early stopping, best iteration is:
[105] training's multi_logloss: 0.159637 valid_1's multi_logloss: 0.170937
feature_fraction, val_score: 0.163806: 43%|####2 | 3/7 [00:29<00:39, 9.91s/it][I 2020-10-05 01:39:26,752] Trial 2 finished with value: 0.17093706343651485 and parameters: {'feature_fraction': 0.8999999999999999}. Best is trial 1 with value: 0.16380641954973035.
feature_fraction, val_score: 0.163806: 43%|####2 | 3/7 [00:29<00:39, 9.91s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.165649 valid_1's multi_logloss: 0.175603
[200] training's multi_logloss: 0.149261 valid_1's multi_logloss: 0.167375
[300] training's multi_logloss: 0.140256 valid_1's multi_logloss: 0.165219
[400] training's multi_logloss: 0.133317 valid_1's multi_logloss: 0.164255
[500] training's multi_logloss: 0.127339 valid_1's multi_logloss: 0.163815
Early stopping, best iteration is:
[531] training's multi_logloss: 0.125601 valid_1's multi_logloss: 0.163628
feature_fraction, val_score: 0.163628: 57%|#####7 | 4/7 [00:47<00:36, 12.16s/it][I 2020-10-05 01:39:44,146] Trial 3 finished with value: 0.16362763441902556 and parameters: {'feature_fraction': 0.5}. Best is trial 3 with value: 0.16362763441902556.
feature_fraction, val_score: 0.163628: 57%|#####7 | 4/7 [00:47<00:36, 12.16s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.160287 valid_1's multi_logloss: 0.171711
Early stopping, best iteration is:
[130] training's multi_logloss: 0.154765 valid_1's multi_logloss: 0.169293
feature_fraction, val_score: 0.163628: 71%|#######1 | 5/7 [00:57<00:23, 11.58s/it][I 2020-10-05 01:39:54,386] Trial 4 finished with value: 0.16929348050036375 and parameters: {'feature_fraction': 1.0}. Best is trial 3 with value: 0.16362763441902556.
feature_fraction, val_score: 0.163628: 71%|#######1 | 5/7 [00:57<00:23, 11.58s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.161738 valid_1's multi_logloss: 0.173028
Early stopping, best iteration is:
[114] training's multi_logloss: 0.158324 valid_1's multi_logloss: 0.170882
feature_fraction, val_score: 0.163628: 86%|########5 | 6/7 [01:02<00:09, 9.64s/it][I 2020-10-05 01:39:59,485] Trial 5 finished with value: 0.1708820358219462 and parameters: {'feature_fraction': 0.8}. Best is trial 3 with value: 0.16362763441902556.
feature_fraction, val_score: 0.163628: 86%|########5 | 6/7 [01:02<00:09, 9.64s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.170758 valid_1's multi_logloss: 0.180113
[200] training's multi_logloss: 0.152064 valid_1's multi_logloss: 0.168935
[300] training's multi_logloss: 0.14251 valid_1's multi_logloss: 0.165979
[400] training's multi_logloss: 0.135389 valid_1's multi_logloss: 0.164762
Early stopping, best iteration is:
[464] training's multi_logloss: 0.131513 valid_1's multi_logloss: 0.164176
feature_fraction, val_score: 0.163628: 100%|##########| 7/7 [01:21<00:00, 12.34s/it][I 2020-10-05 01:40:18,148] Trial 6 finished with value: 0.16417630259249286 and parameters: {'feature_fraction': 0.4}. Best is trial 3 with value: 0.16362763441902556.
feature_fraction, val_score: 0.163628: 100%|##########| 7/7 [01:21<00:00, 11.63s/it]
num_leaves, val_score: 0.163628: 0%| | 0/20 [00:00<?, ?it/s]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.150085 valid_1's multi_logloss: 0.16878
[200] training's multi_logloss: 0.130683 valid_1's multi_logloss: 0.16386
Early stopping, best iteration is:
[262] training's multi_logloss: 0.122812 valid_1's multi_logloss: 0.163395
num_leaves, val_score: 0.163395: 5%|5 | 1/20 [00:09<03:08, 9.90s/it][I 2020-10-05 01:40:28,057] Trial 7 finished with value: 0.1633948316587122 and parameters: {'num_leaves': 67}. Best is trial 7 with value: 0.1633948316587122.
num_leaves, val_score: 0.163395: 5%|5 | 1/20 [00:09<03:08, 9.90s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.13437 valid_1's multi_logloss: 0.165749
Early stopping, best iteration is:
[183] training's multi_logloss: 0.11309 valid_1's multi_logloss: 0.162617
num_leaves, val_score: 0.162617: 10%|# | 2/20 [00:18<02:51, 9.50s/it][I 2020-10-05 01:40:36,638] Trial 8 finished with value: 0.16261715791253684 and parameters: {'num_leaves': 128}. Best is trial 8 with value: 0.16261715791253684.
num_leaves, val_score: 0.162617: 10%|# | 2/20 [00:18<02:51, 9.50s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.147506 valid_1's multi_logloss: 0.168034
[200] training's multi_logloss: 0.127448 valid_1's multi_logloss: 0.163461
Early stopping, best iteration is:
[248] training's multi_logloss: 0.120832 valid_1's multi_logloss: 0.16294
num_leaves, val_score: 0.162617: 15%|#5 | 3/20 [00:29<02:48, 9.89s/it][I 2020-10-05 01:40:47,429] Trial 9 finished with value: 0.16294025794772124 and parameters: {'num_leaves': 75}. Best is trial 8 with value: 0.16261715791253684.
num_leaves, val_score: 0.162617: 15%|#5 | 3/20 [00:29<02:48, 9.89s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.113822 valid_1's multi_logloss: 0.163663
Early stopping, best iteration is:
[142] training's multi_logloss: 0.0983114 valid_1's multi_logloss: 0.162338
num_leaves, val_score: 0.162338: 20%|## | 4/20 [00:43<02:58, 11.16s/it][I 2020-10-05 01:41:01,552] Trial 10 finished with value: 0.16233830008380942 and parameters: {'num_leaves': 243}. Best is trial 10 with value: 0.16233830008380942.
num_leaves, val_score: 0.162338: 20%|## | 4/20 [00:43<02:58, 11.16s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115402 valid_1's multi_logloss: 0.163998
Early stopping, best iteration is:
[165] training's multi_logloss: 0.093376 valid_1's multi_logloss: 0.162661
num_leaves, val_score: 0.162338: 25%|##5 | 5/20 [00:53<02:44, 10.95s/it][I 2020-10-05 01:41:12,018] Trial 11 finished with value: 0.1626607908036498 and parameters: {'num_leaves': 233}. Best is trial 10 with value: 0.16233830008380942.
num_leaves, val_score: 0.162338: 25%|##5 | 5/20 [00:53<02:44, 10.95s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.121582 valid_1's multi_logloss: 0.164385
Early stopping, best iteration is:
[165] training's multi_logloss: 0.101027 valid_1's multi_logloss: 0.162603
num_leaves, val_score: 0.162338: 30%|### | 6/20 [01:03<02:27, 10.51s/it][I 2020-10-05 01:41:21,487] Trial 12 finished with value: 0.16260300356495658 and parameters: {'num_leaves': 195}. Best is trial 10 with value: 0.16233830008380942.
num_leaves, val_score: 0.162338: 30%|### | 6/20 [01:03<02:27, 10.51s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.11569 valid_1's multi_logloss: 0.163916
Early stopping, best iteration is:
[154] training's multi_logloss: 0.0968509 valid_1's multi_logloss: 0.162224
num_leaves, val_score: 0.162224: 35%|###5 | 7/20 [01:13<02:14, 10.34s/it][I 2020-10-05 01:41:31,435] Trial 13 finished with value: 0.16222355114345732 and parameters: {'num_leaves': 231}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 35%|###5 | 7/20 [01:13<02:14, 10.34s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.112095 valid_1's multi_logloss: 0.16367
Early stopping, best iteration is:
[142] training's multi_logloss: 0.0962171 valid_1's multi_logloss: 0.162379
num_leaves, val_score: 0.162224: 40%|#### | 8/20 [01:22<02:00, 10.05s/it][I 2020-10-05 01:41:40,807] Trial 14 finished with value: 0.16237915241116044 and parameters: {'num_leaves': 255}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 40%|#### | 8/20 [01:22<02:00, 10.05s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.119369 valid_1's multi_logloss: 0.164238
Early stopping, best iteration is:
[158] training's multi_logloss: 0.100064 valid_1's multi_logloss: 0.162377
num_leaves, val_score: 0.162224: 45%|####5 | 9/20 [01:31<01:47, 9.79s/it][I 2020-10-05 01:41:49,978] Trial 15 finished with value: 0.16237721560017102 and parameters: {'num_leaves': 208}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 45%|####5 | 9/20 [01:31<01:47, 9.79s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.129841 valid_1's multi_logloss: 0.165067
[200] training's multi_logloss: 0.103666 valid_1's multi_logloss: 0.162631
Early stopping, best iteration is:
[195] training's multi_logloss: 0.104686 valid_1's multi_logloss: 0.162603
num_leaves, val_score: 0.162224: 50%|##### | 10/20 [01:41<01:37, 9.79s/it][I 2020-10-05 01:41:59,780] Trial 16 finished with value: 0.16260282042518934 and parameters: {'num_leaves': 150}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 50%|##### | 10/20 [01:41<01:37, 9.79s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.112095 valid_1's multi_logloss: 0.16367
Early stopping, best iteration is:
[142] training's multi_logloss: 0.0962171 valid_1's multi_logloss: 0.162379
num_leaves, val_score: 0.162224: 55%|#####5 | 11/20 [01:51<01:29, 9.90s/it][I 2020-10-05 01:42:09,928] Trial 17 finished with value: 0.16237915241116044 and parameters: {'num_leaves': 255}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 55%|#####5 | 11/20 [01:51<01:29, 9.90s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.125475 valid_1's multi_logloss: 0.16473
Early stopping, best iteration is:
[156] training's multi_logloss: 0.108027 valid_1's multi_logloss: 0.162763
num_leaves, val_score: 0.162224: 60%|###### | 12/20 [02:01<01:18, 9.78s/it][I 2020-10-05 01:42:19,440] Trial 18 finished with value: 0.16276280677618915 and parameters: {'num_leaves': 172}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 60%|###### | 12/20 [02:01<01:18, 9.78s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.112095 valid_1's multi_logloss: 0.16367
Early stopping, best iteration is:
[142] training's multi_logloss: 0.0962171 valid_1's multi_logloss: 0.162379
num_leaves, val_score: 0.162224: 65%|######5 | 13/20 [02:11<01:10, 10.02s/it][I 2020-10-05 01:42:30,015] Trial 19 finished with value: 0.16237915241116044 and parameters: {'num_leaves': 255}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 65%|######5 | 13/20 [02:11<01:10, 10.02s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.118248 valid_1's multi_logloss: 0.164028
Early stopping, best iteration is:
[159] training's multi_logloss: 0.0983824 valid_1's multi_logloss: 0.162364
num_leaves, val_score: 0.162224: 70%|####### | 14/20 [02:23<01:02, 10.42s/it][I 2020-10-05 01:42:41,378] Trial 20 finished with value: 0.16236442115335945 and parameters: {'num_leaves': 215}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 70%|####### | 14/20 [02:23<01:02, 10.42s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.11743 valid_1's multi_logloss: 0.164095
Early stopping, best iteration is:
[158] training's multi_logloss: 0.0974664 valid_1's multi_logloss: 0.162342
num_leaves, val_score: 0.162224: 75%|#######5 | 15/20 [02:34<00:53, 10.68s/it][I 2020-10-05 01:42:52,664] Trial 21 finished with value: 0.1623416323842142 and parameters: {'num_leaves': 220}. Best is trial 13 with value: 0.16222355114345732.
num_leaves, val_score: 0.162224: 75%|#######5 | 15/20 [02:34<00:53, 10.68s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.11553 valid_1's multi_logloss: 0.16354
Early stopping, best iteration is:
[155] training's multi_logloss: 0.0964272 valid_1's multi_logloss: 0.162102
num_leaves, val_score: 0.162102: 80%|######## | 16/20 [02:45<00:43, 10.88s/it][I 2020-10-05 01:43:04,015] Trial 22 finished with value: 0.16210203791715908 and parameters: {'num_leaves': 232}. Best is trial 22 with value: 0.16210203791715908.
num_leaves, val_score: 0.162102: 80%|######## | 16/20 [02:45<00:43, 10.88s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.176055 valid_1's multi_logloss: 0.18274
[200] training's multi_logloss: 0.159619 valid_1's multi_logloss: 0.171477
Early stopping, best iteration is:
[215] training's multi_logloss: 0.158132 valid_1's multi_logloss: 0.170663
num_leaves, val_score: 0.162102: 85%|########5 | 17/20 [02:53<00:29, 9.97s/it][I 2020-10-05 01:43:11,860] Trial 23 finished with value: 0.1706630522857091 and parameters: {'num_leaves': 19}. Best is trial 22 with value: 0.16210203791715908.
num_leaves, val_score: 0.162102: 85%|########5 | 17/20 [02:53<00:29, 9.97s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.124357 valid_1's multi_logloss: 0.16471
Early stopping, best iteration is:
[166] training's multi_logloss: 0.104317 valid_1's multi_logloss: 0.162603
num_leaves, val_score: 0.162102: 90%|######### | 18/20 [03:05<00:20, 10.39s/it][I 2020-10-05 01:43:23,219] Trial 24 finished with value: 0.16260324998196404 and parameters: {'num_leaves': 179}. Best is trial 22 with value: 0.16210203791715908.
num_leaves, val_score: 0.162102: 90%|######### | 18/20 [03:05<00:20, 10.39s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114898 valid_1's multi_logloss: 0.163815
Early stopping, best iteration is:
[153] training's multi_logloss: 0.096125 valid_1's multi_logloss: 0.162262
num_leaves, val_score: 0.162102: 95%|#########5| 19/20 [03:16<00:10, 10.78s/it][I 2020-10-05 01:43:34,904] Trial 25 finished with value: 0.1622623114693665 and parameters: {'num_leaves': 237}. Best is trial 22 with value: 0.16210203791715908.
num_leaves, val_score: 0.162102: 95%|#########5| 19/20 [03:16<00:10, 10.78s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.135095 valid_1's multi_logloss: 0.165697
Early stopping, best iteration is:
[173] training's multi_logloss: 0.115912 valid_1's multi_logloss: 0.16288
num_leaves, val_score: 0.162102: 100%|##########| 20/20 [03:26<00:00, 10.33s/it][I 2020-10-05 01:43:44,206] Trial 26 finished with value: 0.16287975139034827 and parameters: {'num_leaves': 125}. Best is trial 22 with value: 0.16210203791715908.
num_leaves, val_score: 0.162102: 100%|##########| 20/20 [03:26<00:00, 10.30s/it]
bagging, val_score: 0.162102: 0%| | 0/10 [00:00<?, ?it/s]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115842 valid_1's multi_logloss: 0.163836
Early stopping, best iteration is:
[159] training's multi_logloss: 0.0949288 valid_1's multi_logloss: 0.162088
bagging, val_score: 0.162088: 10%|# | 1/10 [00:10<01:38, 10.96s/it][I 2020-10-05 01:43:55,179] Trial 27 finished with value: 0.1620877679754371 and parameters: {'bagging_fraction': 0.8713477624436328, 'bagging_freq': 5}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 10%|# | 1/10 [00:10<01:38, 10.96s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115669 valid_1's multi_logloss: 0.164101
Early stopping, best iteration is:
[157] training's multi_logloss: 0.0951842 valid_1's multi_logloss: 0.162401
bagging, val_score: 0.162088: 20%|## | 2/10 [00:21<01:26, 10.82s/it][I 2020-10-05 01:44:05,681] Trial 28 finished with value: 0.16240084080295847 and parameters: {'bagging_fraction': 0.8886806944631855, 'bagging_freq': 5}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 20%|## | 2/10 [00:21<01:26, 10.82s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.117368 valid_1's multi_logloss: 0.164542
Early stopping, best iteration is:
[149] training's multi_logloss: 0.0989798 valid_1's multi_logloss: 0.163361
bagging, val_score: 0.162088: 30%|### | 3/10 [00:31<01:13, 10.51s/it][I 2020-10-05 01:44:15,479] Trial 29 finished with value: 0.16336100572898682 and parameters: {'bagging_fraction': 0.5681932661011941, 'bagging_freq': 2}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 30%|### | 3/10 [00:31<01:13, 10.51s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115516 valid_1's multi_logloss: 0.163795
Early stopping, best iteration is:
[155] training's multi_logloss: 0.0961473 valid_1's multi_logloss: 0.162374
bagging, val_score: 0.162088: 40%|#### | 4/10 [00:42<01:05, 10.85s/it][I 2020-10-05 01:44:27,115] Trial 30 finished with value: 0.1623740442728427 and parameters: {'bagging_fraction': 0.9775794746513194, 'bagging_freq': 7}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 40%|#### | 4/10 [00:42<01:05, 10.85s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.1162 valid_1's multi_logloss: 0.164003
Early stopping, best iteration is:
[148] training's multi_logloss: 0.0985721 valid_1's multi_logloss: 0.162386
bagging, val_score: 0.162088: 50%|##### | 5/10 [00:53<00:53, 10.74s/it][I 2020-10-05 01:44:37,594] Trial 31 finished with value: 0.16238600797292838 and parameters: {'bagging_fraction': 0.7757330938405489, 'bagging_freq': 5}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 50%|##### | 5/10 [00:53<00:53, 10.74s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.118878 valid_1's multi_logloss: 0.164902
Early stopping, best iteration is:
[134] training's multi_logloss: 0.105612 valid_1's multi_logloss: 0.163776
bagging, val_score: 0.162088: 60%|###### | 6/10 [01:02<00:40, 10.24s/it][I 2020-10-05 01:44:46,683] Trial 32 finished with value: 0.16377610052662436 and parameters: {'bagging_fraction': 0.4255315208181163, 'bagging_freq': 2}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 60%|###### | 6/10 [01:02<00:40, 10.24s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.116585 valid_1's multi_logloss: 0.164377
Early stopping, best iteration is:
[144] training's multi_logloss: 0.0997517 valid_1's multi_logloss: 0.163076
bagging, val_score: 0.162088: 70%|####### | 7/10 [01:12<00:30, 10.19s/it][I 2020-10-05 01:44:56,743] Trial 33 finished with value: 0.16307643077787534 and parameters: {'bagging_fraction': 0.7525176997746762, 'bagging_freq': 7}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 70%|####### | 7/10 [01:12<00:30, 10.19s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115468 valid_1's multi_logloss: 0.1639
Early stopping, best iteration is:
[155] training's multi_logloss: 0.0959966 valid_1's multi_logloss: 0.162265
bagging, val_score: 0.162088: 80%|######## | 8/10 [01:23<00:20, 10.40s/it][I 2020-10-05 01:45:07,637] Trial 34 finished with value: 0.1622653832358846 and parameters: {'bagging_fraction': 0.9861921068861398, 'bagging_freq': 4}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 80%|######## | 8/10 [01:23<00:20, 10.40s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.117607 valid_1's multi_logloss: 0.164824
Early stopping, best iteration is:
[149] training's multi_logloss: 0.0992214 valid_1's multi_logloss: 0.163512
bagging, val_score: 0.162088: 90%|######### | 9/10 [01:33<00:10, 10.26s/it][I 2020-10-05 01:45:17,564] Trial 35 finished with value: 0.1635119517922178 and parameters: {'bagging_fraction': 0.6114784429051928, 'bagging_freq': 6}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 90%|######### | 9/10 [01:33<00:10, 10.26s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115761 valid_1's multi_logloss: 0.164004
Early stopping, best iteration is:
[165] training's multi_logloss: 0.0930721 valid_1's multi_logloss: 0.162492
bagging, val_score: 0.162088: 100%|##########| 10/10 [01:44<00:00, 10.67s/it][I 2020-10-05 01:45:29,181] Trial 36 finished with value: 0.1624918021211458 and parameters: {'bagging_fraction': 0.8671070660255529, 'bagging_freq': 3}. Best is trial 27 with value: 0.1620877679754371.
bagging, val_score: 0.162088: 100%|##########| 10/10 [01:44<00:00, 10.50s/it]
feature_fraction_stage2, val_score: 0.162088: 0%| | 0/6 [00:00<?, ?it/s]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115842 valid_1's multi_logloss: 0.163836
Early stopping, best iteration is:
[159] training's multi_logloss: 0.0949288 valid_1's multi_logloss: 0.162088
feature_fraction_stage2, val_score: 0.162088: 17%|#6 | 1/6 [00:10<00:54, 10.87s/it][I 2020-10-05 01:45:40,073] Trial 37 finished with value: 0.1620877679754371 and parameters: {'feature_fraction': 0.516}. Best is trial 37 with value: 0.1620877679754371.
feature_fraction_stage2, val_score: 0.162088: 17%|#6 | 1/6 [00:10<00:54, 10.87s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.120798 valid_1's multi_logloss: 0.166608
Early stopping, best iteration is:
[187] training's multi_logloss: 0.0909902 valid_1's multi_logloss: 0.163141
feature_fraction_stage2, val_score: 0.162088: 33%|###3 | 2/6 [00:23<00:45, 11.46s/it][I 2020-10-05 01:45:52,891] Trial 38 finished with value: 0.16314079654316815 and parameters: {'feature_fraction': 0.42}. Best is trial 37 with value: 0.1620877679754371.
feature_fraction_stage2, val_score: 0.162088: 33%|###3 | 2/6 [00:23<00:45, 11.46s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.117827 valid_1's multi_logloss: 0.164479
Early stopping, best iteration is:
[144] training's multi_logloss: 0.101044 valid_1's multi_logloss: 0.1624
feature_fraction_stage2, val_score: 0.162088: 50%|##### | 3/6 [00:34<00:33, 11.12s/it][I 2020-10-05 01:46:03,220] Trial 39 finished with value: 0.16240010191948395 and parameters: {'feature_fraction': 0.484}. Best is trial 37 with value: 0.1620877679754371.
feature_fraction_stage2, val_score: 0.162088: 50%|##### | 3/6 [00:34<00:33, 11.12s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.117827 valid_1's multi_logloss: 0.164479
Early stopping, best iteration is:
[144] training's multi_logloss: 0.101044 valid_1's multi_logloss: 0.1624
feature_fraction_stage2, val_score: 0.162088: 67%|######6 | 4/6 [00:44<00:21, 10.87s/it][I 2020-10-05 01:46:13,504] Trial 40 finished with value: 0.16240010191948395 and parameters: {'feature_fraction': 0.45199999999999996}. Best is trial 37 with value: 0.1620877679754371.
feature_fraction_stage2, val_score: 0.162088: 67%|######6 | 4/6 [00:44<00:21, 10.87s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114238 valid_1's multi_logloss: 0.163253
Early stopping, best iteration is:
[147] training's multi_logloss: 0.0974959 valid_1's multi_logloss: 0.162036
feature_fraction_stage2, val_score: 0.162036: 83%|########3 | 5/6 [00:54<00:10, 10.73s/it][I 2020-10-05 01:46:23,910] Trial 41 finished with value: 0.16203598423148052 and parameters: {'feature_fraction': 0.58}. Best is trial 41 with value: 0.16203598423148052.
feature_fraction_stage2, val_score: 0.162036: 83%|########3 | 5/6 [00:54<00:10, 10.73s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115842 valid_1's multi_logloss: 0.163836
Early stopping, best iteration is:
[159] training's multi_logloss: 0.0949288 valid_1's multi_logloss: 0.162088
feature_fraction_stage2, val_score: 0.162036: 100%|##########| 6/6 [01:05<00:00, 10.83s/it][I 2020-10-05 01:46:34,966] Trial 42 finished with value: 0.1620877679754371 and parameters: {'feature_fraction': 0.5479999999999999}. Best is trial 41 with value: 0.16203598423148052.
feature_fraction_stage2, val_score: 0.162036: 100%|##########| 6/6 [01:05<00:00, 10.96s/it]
regularization_factors, val_score: 0.162036: 0%| | 0/20 [00:00<?, ?it/s]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.11423 valid_1's multi_logloss: 0.163224
Early stopping, best iteration is:
[137] training's multi_logloss: 0.100596 valid_1's multi_logloss: 0.16214
regularization_factors, val_score: 0.162036: 5%|5 | 1/20 [00:10<03:14, 10.23s/it][I 2020-10-05 01:46:45,213] Trial 43 finished with value: 0.16213993619831954 and parameters: {'lambda_l1': 2.737377867689276e-07, 'lambda_l2': 9.151388396395205e-05}. Best is trial 43 with value: 0.16213993619831954.
regularization_factors, val_score: 0.162036: 5%|5 | 1/20 [00:10<03:14, 10.23s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.13737 valid_1's multi_logloss: 0.165753
[200] training's multi_logloss: 0.115654 valid_1's multi_logloss: 0.162753
Early stopping, best iteration is:
[201] training's multi_logloss: 0.115488 valid_1's multi_logloss: 0.162735
regularization_factors, val_score: 0.162036: 10%|# | 2/20 [00:24<03:23, 11.33s/it][I 2020-10-05 01:46:59,115] Trial 44 finished with value: 0.16273540769580838 and parameters: {'lambda_l1': 5.616299389204908, 'lambda_l2': 9.911250368472304}. Best is trial 43 with value: 0.16213993619831954.
regularization_factors, val_score: 0.162036: 10%|# | 2/20 [00:24<03:23, 11.33s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.123488 valid_1's multi_logloss: 0.163763
Early stopping, best iteration is:
[170] training's multi_logloss: 0.10233 valid_1's multi_logloss: 0.162141
regularization_factors, val_score: 0.162036: 15%|#5 | 3/20 [00:36<03:16, 11.54s/it][I 2020-10-05 01:47:11,149] Trial 45 finished with value: 0.16214066259839668 and parameters: {'lambda_l1': 2.1519596207674128, 'lambda_l2': 4.6125717451863005e-08}. Best is trial 43 with value: 0.16213993619831954.
regularization_factors, val_score: 0.162036: 15%|#5 | 3/20 [00:36<03:16, 11.54s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.1238 valid_1's multi_logloss: 0.164048
Early stopping, best iteration is:
[155] training's multi_logloss: 0.106531 valid_1's multi_logloss: 0.162269
regularization_factors, val_score: 0.162036: 20%|## | 4/20 [00:50<03:16, 12.26s/it][I 2020-10-05 01:47:25,073] Trial 46 finished with value: 0.16226872763053296 and parameters: {'lambda_l1': 1.5311561670646566e-08, 'lambda_l2': 6.882260323572732}. Best is trial 43 with value: 0.16213993619831954.
regularization_factors, val_score: 0.162036: 20%|## | 4/20 [00:50<03:16, 12.26s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114194 valid_1's multi_logloss: 0.163385
Early stopping, best iteration is:
[141] training's multi_logloss: 0.099175 valid_1's multi_logloss: 0.162368
regularization_factors, val_score: 0.162036: 25%|##5 | 5/20 [01:09<03:37, 14.50s/it][I 2020-10-05 01:47:44,803] Trial 47 finished with value: 0.1623678901503559 and parameters: {'lambda_l1': 0.0005448057993686177, 'lambda_l2': 5.121791403463975e-08}. Best is trial 43 with value: 0.16213993619831954.
regularization_factors, val_score: 0.162036: 25%|##5 | 5/20 [01:09<03:37, 14.50s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.11424 valid_1's multi_logloss: 0.163359
Early stopping, best iteration is:
[155] training's multi_logloss: 0.0949821 valid_1's multi_logloss: 0.162132
regularization_factors, val_score: 0.162036: 30%|### | 6/20 [01:25<03:27, 14.84s/it][I 2020-10-05 01:48:00,438] Trial 48 finished with value: 0.16213221126715713 and parameters: {'lambda_l1': 0.0007723294399190148, 'lambda_l2': 0.0042048908933122395}. Best is trial 48 with value: 0.16213221126715713.
regularization_factors, val_score: 0.162036: 30%|### | 6/20 [01:25<03:27, 14.84s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114365 valid_1's multi_logloss: 0.163106
Early stopping, best iteration is:
[143] training's multi_logloss: 0.0987875 valid_1's multi_logloss: 0.162099
regularization_factors, val_score: 0.162036: 35%|###5 | 7/20 [01:37<03:01, 13.93s/it][I 2020-10-05 01:48:12,257] Trial 49 finished with value: 0.16209917281696537 and parameters: {'lambda_l1': 2.0516618958043193e-06, 'lambda_l2': 0.0008841325123849131}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 35%|###5 | 7/20 [01:37<03:01, 13.93s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114339 valid_1's multi_logloss: 0.163447
Early stopping, best iteration is:
[133] training's multi_logloss: 0.101937 valid_1's multi_logloss: 0.162351
regularization_factors, val_score: 0.162036: 40%|#### | 8/20 [01:46<02:30, 12.55s/it][I 2020-10-05 01:48:21,578] Trial 50 finished with value: 0.16235102725063633 and parameters: {'lambda_l1': 3.200783717728594e-06, 'lambda_l2': 0.0016579361992030447}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 40%|#### | 8/20 [01:46<02:30, 12.55s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114127 valid_1's multi_logloss: 0.16348
Early stopping, best iteration is:
[143] training's multi_logloss: 0.0986415 valid_1's multi_logloss: 0.16254
regularization_factors, val_score: 0.162036: 45%|####5 | 9/20 [01:56<02:08, 11.71s/it][I 2020-10-05 01:48:31,316] Trial 51 finished with value: 0.16254010022503304 and parameters: {'lambda_l1': 9.959907115384746e-06, 'lambda_l2': 1.0008735818272323e-05}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 45%|####5 | 9/20 [01:56<02:08, 11.71s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115182 valid_1's multi_logloss: 0.163427
Early stopping, best iteration is:
[158] training's multi_logloss: 0.0952347 valid_1's multi_logloss: 0.162259
regularization_factors, val_score: 0.162036: 50%|##### | 10/20 [02:07<01:55, 11.57s/it][I 2020-10-05 01:48:42,552] Trial 52 finished with value: 0.1622585208871488 and parameters: {'lambda_l1': 0.01857887945756072, 'lambda_l2': 0.22498727332043805}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 50%|##### | 10/20 [02:07<01:55, 11.57s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114185 valid_1's multi_logloss: 0.163329
Early stopping, best iteration is:
[152] training's multi_logloss: 0.0959258 valid_1's multi_logloss: 0.162526
regularization_factors, val_score: 0.162036: 55%|#####5 | 11/20 [02:18<01:43, 11.48s/it][I 2020-10-05 01:48:53,817] Trial 53 finished with value: 0.16252607084337764 and parameters: {'lambda_l1': 2.0226575516207603e-08, 'lambda_l2': 1.237595213185944e-06}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 55%|#####5 | 11/20 [02:18<01:43, 11.48s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114405 valid_1's multi_logloss: 0.163306
Early stopping, best iteration is:
[137] training's multi_logloss: 0.100944 valid_1's multi_logloss: 0.162227
regularization_factors, val_score: 0.162036: 60%|###### | 12/20 [02:29<01:29, 11.19s/it][I 2020-10-05 01:49:04,338] Trial 54 finished with value: 0.16222749212089208 and parameters: {'lambda_l1': 7.716652058064478e-06, 'lambda_l2': 0.03831506886393764}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 60%|###### | 12/20 [02:29<01:29, 11.19s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114408 valid_1's multi_logloss: 0.16349
Early stopping, best iteration is:
[143] training's multi_logloss: 0.0988651 valid_1's multi_logloss: 0.162504
regularization_factors, val_score: 0.162036: 65%|######5 | 13/20 [02:40<01:17, 11.05s/it][I 2020-10-05 01:49:15,049] Trial 55 finished with value: 0.16250393480853328 and parameters: {'lambda_l1': 0.0397494610177511, 'lambda_l2': 3.491880854311525e-05}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 65%|######5 | 13/20 [02:40<01:17, 11.05s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114578 valid_1's multi_logloss: 0.163602
Early stopping, best iteration is:
[149] training's multi_logloss: 0.0971587 valid_1's multi_logloss: 0.162246
regularization_factors, val_score: 0.162036: 70%|####### | 14/20 [02:50<01:05, 10.96s/it][I 2020-10-05 01:49:25,794] Trial 56 finished with value: 0.16224556156010456 and parameters: {'lambda_l1': 2.9831412097747654e-07, 'lambda_l2': 0.06764896441300657}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 70%|####### | 14/20 [02:50<01:05, 10.96s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114128 valid_1's multi_logloss: 0.163086
Early stopping, best iteration is:
[143] training's multi_logloss: 0.0985553 valid_1's multi_logloss: 0.162141
regularization_factors, val_score: 0.162036: 75%|#######5 | 15/20 [03:01<00:54, 10.86s/it][I 2020-10-05 01:49:36,444] Trial 57 finished with value: 0.16214117108329165 and parameters: {'lambda_l1': 5.571366596823703e-05, 'lambda_l2': 1.1185338510339606e-06}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 75%|#######5 | 15/20 [03:01<00:54, 10.86s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114268 valid_1's multi_logloss: 0.163263
Early stopping, best iteration is:
[124] training's multi_logloss: 0.104901 valid_1's multi_logloss: 0.162238
regularization_factors, val_score: 0.162036: 80%|######## | 16/20 [03:12<00:43, 10.77s/it][I 2020-10-05 01:49:46,998] Trial 58 finished with value: 0.1622377681164801 and parameters: {'lambda_l1': 2.2342344009077944e-07, 'lambda_l2': 0.0009265964422642836}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 80%|######## | 16/20 [03:12<00:43, 10.77s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114294 valid_1's multi_logloss: 0.16334
Early stopping, best iteration is:
[127] training's multi_logloss: 0.104043 valid_1's multi_logloss: 0.162184
regularization_factors, val_score: 0.162036: 85%|########5 | 17/20 [03:21<00:31, 10.36s/it][I 2020-10-05 01:49:56,405] Trial 59 finished with value: 0.1621840348879034 and parameters: {'lambda_l1': 0.02743298446075123, 'lambda_l2': 0.010389398930529176}. Best is trial 49 with value: 0.16209917281696537.
regularization_factors, val_score: 0.162036: 85%|########5 | 17/20 [03:21<00:31, 10.36s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.116446 valid_1's multi_logloss: 0.163248
Early stopping, best iteration is:
[161] training's multi_logloss: 0.0960004 valid_1's multi_logloss: 0.161803
regularization_factors, val_score: 0.161803: 90%|######### | 18/20 [03:32<00:21, 10.67s/it][I 2020-10-05 01:50:07,807] Trial 60 finished with value: 0.16180307845830263 and parameters: {'lambda_l1': 0.002157343741168164, 'lambda_l2': 0.6844996577650422}. Best is trial 60 with value: 0.16180307845830263.
regularization_factors, val_score: 0.161803: 90%|######### | 18/20 [03:32<00:21, 10.67s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.118633 valid_1's multi_logloss: 0.163468
Early stopping, best iteration is:
[150] training's multi_logloss: 0.101832 valid_1's multi_logloss: 0.161919
regularization_factors, val_score: 0.161803: 95%|#########5| 19/20 [03:44<00:10, 10.83s/it][I 2020-10-05 01:50:19,012] Trial 61 finished with value: 0.16191902449823384 and parameters: {'lambda_l1': 0.004938765369111081, 'lambda_l2': 1.883234137966169}. Best is trial 60 with value: 0.16180307845830263.
regularization_factors, val_score: 0.161803: 95%|#########5| 19/20 [03:44<00:10, 10.83s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.11704 valid_1's multi_logloss: 0.163295
Early stopping, best iteration is:
[151] training's multi_logloss: 0.0993753 valid_1's multi_logloss: 0.162078
regularization_factors, val_score: 0.161803: 100%|##########| 20/20 [03:54<00:00, 10.87s/it][I 2020-10-05 01:50:29,954] Trial 62 finished with value: 0.1620782159582214 and parameters: {'lambda_l1': 0.002352063059463711, 'lambda_l2': 0.9678149953457204}. Best is trial 60 with value: 0.16180307845830263.
regularization_factors, val_score: 0.161803: 100%|##########| 20/20 [03:54<00:00, 11.75s/it]
min_data_in_leaf, val_score: 0.161803: 0%| | 0/5 [00:00<?, ?it/s]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.121836 valid_1's multi_logloss: 0.163592
Early stopping, best iteration is:
[147] training's multi_logloss: 0.105574 valid_1's multi_logloss: 0.162165
min_data_in_leaf, val_score: 0.161803: 20%|## | 1/5 [00:10<00:40, 10.21s/it][I 2020-10-05 01:50:40,179] Trial 63 finished with value: 0.1621645138673385 and parameters: {'min_child_samples': 100}. Best is trial 63 with value: 0.1621645138673385.
min_data_in_leaf, val_score: 0.161803: 20%|## | 1/5 [00:10<00:40, 10.21s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.115276 valid_1's multi_logloss: 0.163448
Early stopping, best iteration is:
[166] training's multi_logloss: 0.0932289 valid_1's multi_logloss: 0.162097
min_data_in_leaf, val_score: 0.161803: 40%|#### | 2/5 [00:22<00:32, 10.74s/it][I 2020-10-05 01:50:52,146] Trial 64 finished with value: 0.1620967491411566 and parameters: {'min_child_samples': 10}. Best is trial 64 with value: 0.1620967491411566.
min_data_in_leaf, val_score: 0.161803: 40%|#### | 2/5 [00:22<00:32, 10.74s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.118865 valid_1's multi_logloss: 0.163391
Early stopping, best iteration is:
[157] training's multi_logloss: 0.0995464 valid_1's multi_logloss: 0.16194
min_data_in_leaf, val_score: 0.161803: 60%|###### | 3/5 [00:33<00:21, 10.80s/it][I 2020-10-05 01:51:03,072] Trial 65 finished with value: 0.1619401524055166 and parameters: {'min_child_samples': 50}. Best is trial 65 with value: 0.1619401524055166.
min_data_in_leaf, val_score: 0.161803: 60%|###### | 3/5 [00:33<00:21, 10.80s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.114807 valid_1's multi_logloss: 0.163714
Early stopping, best iteration is:
[172] training's multi_logloss: 0.0915486 valid_1's multi_logloss: 0.162508
min_data_in_leaf, val_score: 0.161803: 80%|######## | 4/5 [00:47<00:11, 11.81s/it][I 2020-10-05 01:51:17,244] Trial 66 finished with value: 0.16250780944638324 and parameters: {'min_child_samples': 5}. Best is trial 65 with value: 0.1619401524055166.
min_data_in_leaf, val_score: 0.161803: 80%|######## | 4/5 [00:47<00:11, 11.81s/it]
Training until validation scores don't improve for 10 rounds
[100] training's multi_logloss: 0.116787 valid_1's multi_logloss: 0.16349
Early stopping, best iteration is:
[162] training's multi_logloss: 0.0960875 valid_1's multi_logloss: 0.162041
min_data_in_leaf, val_score: 0.161803: 100%|##########| 5/5 [01:00<00:00, 12.14s/it][I 2020-10-05 01:51:30,168] Trial 67 finished with value: 0.1620405229325728 and parameters: {'min_child_samples': 25}. Best is trial 65 with value: 0.1619401524055166.
min_data_in_leaf, val_score: 0.161803: 100%|##########| 5/5 [01:00<00:00, 12.04s/it]
Best params: {'objective': 'multiclass', 'metric': 'multi_logloss', 'num_class': 3, 'lambda_l1': 0.002157343741168164, 'lambda_l2': 0.6844996577650422, 'random_state': 42, 'n_jobs': -1, 'feature_pre_filter': False, 'bagging_freq': 5, 'num_leaves': 232, 'feature_fraction': 0.58, 'bagging_fraction': 0.8713477624436328, 'min_child_samples': 20}
Accuracy = 0.9328125
Params:
objective: multiclass
metric: multi_logloss
num_class: 3
lambda_l1: 0.002157343741168164
lambda_l2: 0.6844996577650422
random_state: 42
n_jobs: -1
feature_pre_filter: False
bagging_freq: 5
num_leaves: 232
feature_fraction: 0.58
bagging_fraction: 0.8713477624436328
min_child_samples: 20
Stratified K-Fold Cross Validation¶
cv = StratifiedKFold(n_splits=n_fold, shuffle=True, random_state=seed)
LightGBM 모델 학습¶
p_val = np.zeros((trn.shape[0], n_class))
p_tst = np.zeros((tst.shape[0], n_class))
for i, (i_trn, i_val) in enumerate(cv.split(trn, y), 1):
print(f'training model for CV #{i}')
clf = LGBMClassifier(**params)
clf.fit(trn[i_trn], y[i_trn],
eval_set=[(trn[i_val], y[i_val])],
eval_metric='multiclass',
early_stopping_rounds=10)
p_val[i_val, :] = clf.predict_proba(trn[i_val])
p_tst += clf.predict_proba(tst) / n_fold
training model for CV #1
[1] valid_0's multi_logloss: 0.887685
Training until validation scores don't improve for 10 rounds
[2] valid_0's multi_logloss: 0.806995
[3] valid_0's multi_logloss: 0.732773
[4] valid_0's multi_logloss: 0.670089
[5] valid_0's multi_logloss: 0.617591
[6] valid_0's multi_logloss: 0.574849
[7] valid_0's multi_logloss: 0.536247
[8] valid_0's multi_logloss: 0.504096
[9] valid_0's multi_logloss: 0.478267
[10] valid_0's multi_logloss: 0.449372
[11] valid_0's multi_logloss: 0.423029
[12] valid_0's multi_logloss: 0.400206
[13] valid_0's multi_logloss: 0.378186
[14] valid_0's multi_logloss: 0.359595
[15] valid_0's multi_logloss: 0.343111
[16] valid_0's multi_logloss: 0.32884
[17] valid_0's multi_logloss: 0.315538
[18] valid_0's multi_logloss: 0.302793
[19] valid_0's multi_logloss: 0.29092
[20] valid_0's multi_logloss: 0.281147
[21] valid_0's multi_logloss: 0.271235
[22] valid_0's multi_logloss: 0.262939
[23] valid_0's multi_logloss: 0.255613
[24] valid_0's multi_logloss: 0.249139
[25] valid_0's multi_logloss: 0.242552
[26] valid_0's multi_logloss: 0.237431
[27] valid_0's multi_logloss: 0.23282
[28] valid_0's multi_logloss: 0.227565
[29] valid_0's multi_logloss: 0.223501
[30] valid_0's multi_logloss: 0.218986
[31] valid_0's multi_logloss: 0.21584
[32] valid_0's multi_logloss: 0.212288
[33] valid_0's multi_logloss: 0.20819
[34] valid_0's multi_logloss: 0.204601
[35] valid_0's multi_logloss: 0.201395
[36] valid_0's multi_logloss: 0.198837
[37] valid_0's multi_logloss: 0.197026
[38] valid_0's multi_logloss: 0.194824
[39] valid_0's multi_logloss: 0.19274
[40] valid_0's multi_logloss: 0.190935
[41] valid_0's multi_logloss: 0.18911
[42] valid_0's multi_logloss: 0.187821
[43] valid_0's multi_logloss: 0.186075
[44] valid_0's multi_logloss: 0.184739
[45] valid_0's multi_logloss: 0.18333
[46] valid_0's multi_logloss: 0.181974
[47] valid_0's multi_logloss: 0.180962
[48] valid_0's multi_logloss: 0.17983
[49] valid_0's multi_logloss: 0.178772
[50] valid_0's multi_logloss: 0.177696
[51] valid_0's multi_logloss: 0.176538
[52] valid_0's multi_logloss: 0.175577
[53] valid_0's multi_logloss: 0.174605
[54] valid_0's multi_logloss: 0.173987
[55] valid_0's multi_logloss: 0.17349
[56] valid_0's multi_logloss: 0.172916
[57] valid_0's multi_logloss: 0.172321
[58] valid_0's multi_logloss: 0.172054
[59] valid_0's multi_logloss: 0.171347
[60] valid_0's multi_logloss: 0.170822
[61] valid_0's multi_logloss: 0.170136
[62] valid_0's multi_logloss: 0.169646
[63] valid_0's multi_logloss: 0.169232
[64] valid_0's multi_logloss: 0.168706
[65] valid_0's multi_logloss: 0.168235
[66] valid_0's multi_logloss: 0.167782
[67] valid_0's multi_logloss: 0.167341
[68] valid_0's multi_logloss: 0.166726
[69] valid_0's multi_logloss: 0.166387
[70] valid_0's multi_logloss: 0.166005
[71] valid_0's multi_logloss: 0.165743
[72] valid_0's multi_logloss: 0.165471
[73] valid_0's multi_logloss: 0.165295
[74] valid_0's multi_logloss: 0.164958
[75] valid_0's multi_logloss: 0.164628
[76] valid_0's multi_logloss: 0.164338
[77] valid_0's multi_logloss: 0.164087
[78] valid_0's multi_logloss: 0.16385
[79] valid_0's multi_logloss: 0.16368
[80] valid_0's multi_logloss: 0.16347
[81] valid_0's multi_logloss: 0.163289
[82] valid_0's multi_logloss: 0.162989
[83] valid_0's multi_logloss: 0.16278
[84] valid_0's multi_logloss: 0.162596
[85] valid_0's multi_logloss: 0.162419
[86] valid_0's multi_logloss: 0.162314
[87] valid_0's multi_logloss: 0.162181
[88] valid_0's multi_logloss: 0.162046
[89] valid_0's multi_logloss: 0.161932
[90] valid_0's multi_logloss: 0.161799
[91] valid_0's multi_logloss: 0.161624
[92] valid_0's multi_logloss: 0.161486
[93] valid_0's multi_logloss: 0.161416
[94] valid_0's multi_logloss: 0.161295
[95] valid_0's multi_logloss: 0.161198
[96] valid_0's multi_logloss: 0.161067
[97] valid_0's multi_logloss: 0.16097
[98] valid_0's multi_logloss: 0.160924
[99] valid_0's multi_logloss: 0.160863
[100] valid_0's multi_logloss: 0.160765
Did not meet early stopping. Best iteration is:
[100] valid_0's multi_logloss: 0.160765
training model for CV #2
[1] valid_0's multi_logloss: 0.88779
Training until validation scores don't improve for 10 rounds
[2] valid_0's multi_logloss: 0.807213
[3] valid_0's multi_logloss: 0.733363
[4] valid_0's multi_logloss: 0.670832
[5] valid_0's multi_logloss: 0.618288
[6] valid_0's multi_logloss: 0.575526
[7] valid_0's multi_logloss: 0.536857
[8] valid_0's multi_logloss: 0.505037
[9] valid_0's multi_logloss: 0.47929
[10] valid_0's multi_logloss: 0.450373
[11] valid_0's multi_logloss: 0.424125
[12] valid_0's multi_logloss: 0.401418
[13] valid_0's multi_logloss: 0.379454
[14] valid_0's multi_logloss: 0.360905
[15] valid_0's multi_logloss: 0.344343
[16] valid_0's multi_logloss: 0.330158
[17] valid_0's multi_logloss: 0.316967
[18] valid_0's multi_logloss: 0.304161
[19] valid_0's multi_logloss: 0.292266
[20] valid_0's multi_logloss: 0.282536
[21] valid_0's multi_logloss: 0.27242
[22] valid_0's multi_logloss: 0.264239
[23] valid_0's multi_logloss: 0.256906
[24] valid_0's multi_logloss: 0.250408
[25] valid_0's multi_logloss: 0.24376
[26] valid_0's multi_logloss: 0.238697
[27] valid_0's multi_logloss: 0.234075
[28] valid_0's multi_logloss: 0.228668
[29] valid_0's multi_logloss: 0.224628
[30] valid_0's multi_logloss: 0.220041
[31] valid_0's multi_logloss: 0.216811
[32] valid_0's multi_logloss: 0.213212
[33] valid_0's multi_logloss: 0.209096
[34] valid_0's multi_logloss: 0.20543
[35] valid_0's multi_logloss: 0.20222
[36] valid_0's multi_logloss: 0.199696
[37] valid_0's multi_logloss: 0.197864
[38] valid_0's multi_logloss: 0.195635
[39] valid_0's multi_logloss: 0.193596
[40] valid_0's multi_logloss: 0.191792
[41] valid_0's multi_logloss: 0.189973
[42] valid_0's multi_logloss: 0.188623
[43] valid_0's multi_logloss: 0.186884
[44] valid_0's multi_logloss: 0.185463
[45] valid_0's multi_logloss: 0.184091
[46] valid_0's multi_logloss: 0.182679
[47] valid_0's multi_logloss: 0.181703
[48] valid_0's multi_logloss: 0.180533
[49] valid_0's multi_logloss: 0.179481
[50] valid_0's multi_logloss: 0.178421
[51] valid_0's multi_logloss: 0.177324
[52] valid_0's multi_logloss: 0.176353
[53] valid_0's multi_logloss: 0.175382
[54] valid_0's multi_logloss: 0.174781
[55] valid_0's multi_logloss: 0.174281
[56] valid_0's multi_logloss: 0.173667
[57] valid_0's multi_logloss: 0.173106
[58] valid_0's multi_logloss: 0.172818
[59] valid_0's multi_logloss: 0.172127
[60] valid_0's multi_logloss: 0.171629
[61] valid_0's multi_logloss: 0.170923
[62] valid_0's multi_logloss: 0.170356
[63] valid_0's multi_logloss: 0.169955
[64] valid_0's multi_logloss: 0.169404
[65] valid_0's multi_logloss: 0.168908
[66] valid_0's multi_logloss: 0.168497
[67] valid_0's multi_logloss: 0.167975
[68] valid_0's multi_logloss: 0.167403
[69] valid_0's multi_logloss: 0.167091
[70] valid_0's multi_logloss: 0.166641
[71] valid_0's multi_logloss: 0.16634
[72] valid_0's multi_logloss: 0.166062
[73] valid_0's multi_logloss: 0.165835
[74] valid_0's multi_logloss: 0.165508
[75] valid_0's multi_logloss: 0.165188
[76] valid_0's multi_logloss: 0.164855
[77] valid_0's multi_logloss: 0.164575
[78] valid_0's multi_logloss: 0.164313
[79] valid_0's multi_logloss: 0.164143
[80] valid_0's multi_logloss: 0.163892
[81] valid_0's multi_logloss: 0.163722
[82] valid_0's multi_logloss: 0.163467
[83] valid_0's multi_logloss: 0.163283
[84] valid_0's multi_logloss: 0.163108
[85] valid_0's multi_logloss: 0.162918
[86] valid_0's multi_logloss: 0.162784
[87] valid_0's multi_logloss: 0.162645
[88] valid_0's multi_logloss: 0.162533
[89] valid_0's multi_logloss: 0.162412
[90] valid_0's multi_logloss: 0.162295
[91] valid_0's multi_logloss: 0.162164
[92] valid_0's multi_logloss: 0.162034
[93] valid_0's multi_logloss: 0.161977
[94] valid_0's multi_logloss: 0.161814
[95] valid_0's multi_logloss: 0.161676
[96] valid_0's multi_logloss: 0.161553
[97] valid_0's multi_logloss: 0.161416
[98] valid_0's multi_logloss: 0.161358
[99] valid_0's multi_logloss: 0.16128
[100] valid_0's multi_logloss: 0.161208
Did not meet early stopping. Best iteration is:
[100] valid_0's multi_logloss: 0.161208
training model for CV #3
[1] valid_0's multi_logloss: 0.888182
Training until validation scores don't improve for 10 rounds
[2] valid_0's multi_logloss: 0.807823
[3] valid_0's multi_logloss: 0.733827
[4] valid_0's multi_logloss: 0.671355
[5] valid_0's multi_logloss: 0.619043
[6] valid_0's multi_logloss: 0.576281
[7] valid_0's multi_logloss: 0.537631
[8] valid_0's multi_logloss: 0.505846
[9] valid_0's multi_logloss: 0.48021
[10] valid_0's multi_logloss: 0.451288
[11] valid_0's multi_logloss: 0.424874
[12] valid_0's multi_logloss: 0.402194
[13] valid_0's multi_logloss: 0.380136
[14] valid_0's multi_logloss: 0.361568
[15] valid_0's multi_logloss: 0.345076
[16] valid_0's multi_logloss: 0.330965
[17] valid_0's multi_logloss: 0.31773
[18] valid_0's multi_logloss: 0.305015
[19] valid_0's multi_logloss: 0.293206
[20] valid_0's multi_logloss: 0.283564
[21] valid_0's multi_logloss: 0.273633
[22] valid_0's multi_logloss: 0.265385
[23] valid_0's multi_logloss: 0.258095
[24] valid_0's multi_logloss: 0.251579
[25] valid_0's multi_logloss: 0.244952
[26] valid_0's multi_logloss: 0.23975
[27] valid_0's multi_logloss: 0.235061
[28] valid_0's multi_logloss: 0.229747
[29] valid_0's multi_logloss: 0.225709
[30] valid_0's multi_logloss: 0.220889
[31] valid_0's multi_logloss: 0.217743
[32] valid_0's multi_logloss: 0.214033
[33] valid_0's multi_logloss: 0.209863
[34] valid_0's multi_logloss: 0.206261
[35] valid_0's multi_logloss: 0.202945
[36] valid_0's multi_logloss: 0.200528
[37] valid_0's multi_logloss: 0.198798
[38] valid_0's multi_logloss: 0.196612
[39] valid_0's multi_logloss: 0.194611
[40] valid_0's multi_logloss: 0.192814
[41] valid_0's multi_logloss: 0.191021
[42] valid_0's multi_logloss: 0.189701
[43] valid_0's multi_logloss: 0.187895
[44] valid_0's multi_logloss: 0.186507
[45] valid_0's multi_logloss: 0.185171
[46] valid_0's multi_logloss: 0.183836
[47] valid_0's multi_logloss: 0.182827
[48] valid_0's multi_logloss: 0.181668
[49] valid_0's multi_logloss: 0.180634
[50] valid_0's multi_logloss: 0.179595
[51] valid_0's multi_logloss: 0.178425
[52] valid_0's multi_logloss: 0.177459
[53] valid_0's multi_logloss: 0.176445
[54] valid_0's multi_logloss: 0.175823
[55] valid_0's multi_logloss: 0.175356
[56] valid_0's multi_logloss: 0.174777
[57] valid_0's multi_logloss: 0.174302
[58] valid_0's multi_logloss: 0.174046
[59] valid_0's multi_logloss: 0.173413
[60] valid_0's multi_logloss: 0.172846
[61] valid_0's multi_logloss: 0.172162
[62] valid_0's multi_logloss: 0.171647
[63] valid_0's multi_logloss: 0.171235
[64] valid_0's multi_logloss: 0.170701
[65] valid_0's multi_logloss: 0.170179
[66] valid_0's multi_logloss: 0.169794
[67] valid_0's multi_logloss: 0.169364
[68] valid_0's multi_logloss: 0.168817
[69] valid_0's multi_logloss: 0.168495
[70] valid_0's multi_logloss: 0.168103
[71] valid_0's multi_logloss: 0.167792
[72] valid_0's multi_logloss: 0.167506
[73] valid_0's multi_logloss: 0.167289
[74] valid_0's multi_logloss: 0.166962
[75] valid_0's multi_logloss: 0.1666
[76] valid_0's multi_logloss: 0.166282
[77] valid_0's multi_logloss: 0.165981
[78] valid_0's multi_logloss: 0.165719
[79] valid_0's multi_logloss: 0.16549
[80] valid_0's multi_logloss: 0.165258
[81] valid_0's multi_logloss: 0.165104
[82] valid_0's multi_logloss: 0.164809
[83] valid_0's multi_logloss: 0.164652
[84] valid_0's multi_logloss: 0.16446
[85] valid_0's multi_logloss: 0.164244
[86] valid_0's multi_logloss: 0.164087
[87] valid_0's multi_logloss: 0.163936
[88] valid_0's multi_logloss: 0.163847
[89] valid_0's multi_logloss: 0.163725
[90] valid_0's multi_logloss: 0.163546
[91] valid_0's multi_logloss: 0.163384
[92] valid_0's multi_logloss: 0.163317
[93] valid_0's multi_logloss: 0.163227
[94] valid_0's multi_logloss: 0.163106
[95] valid_0's multi_logloss: 0.163038
[96] valid_0's multi_logloss: 0.16291
[97] valid_0's multi_logloss: 0.162827
[98] valid_0's multi_logloss: 0.162808
[99] valid_0's multi_logloss: 0.162718
[100] valid_0's multi_logloss: 0.162623
Did not meet early stopping. Best iteration is:
[100] valid_0's multi_logloss: 0.162623
training model for CV #4
[1] valid_0's multi_logloss: 0.888082
Training until validation scores don't improve for 10 rounds
[2] valid_0's multi_logloss: 0.807554
[3] valid_0's multi_logloss: 0.733538
[4] valid_0's multi_logloss: 0.670882
[5] valid_0's multi_logloss: 0.618469
[6] valid_0's multi_logloss: 0.575876
[7] valid_0's multi_logloss: 0.537155
[8] valid_0's multi_logloss: 0.505148
[9] valid_0's multi_logloss: 0.479386
[10] valid_0's multi_logloss: 0.450515
[11] valid_0's multi_logloss: 0.424251
[12] valid_0's multi_logloss: 0.401551
[13] valid_0's multi_logloss: 0.379571
[14] valid_0's multi_logloss: 0.361112
[15] valid_0's multi_logloss: 0.344704
[16] valid_0's multi_logloss: 0.330557
[17] valid_0's multi_logloss: 0.317386
[18] valid_0's multi_logloss: 0.304682
[19] valid_0's multi_logloss: 0.292814
[20] valid_0's multi_logloss: 0.283112
[21] valid_0's multi_logloss: 0.272964
[22] valid_0's multi_logloss: 0.264676
[23] valid_0's multi_logloss: 0.257546
[24] valid_0's multi_logloss: 0.251024
[25] valid_0's multi_logloss: 0.244319
[26] valid_0's multi_logloss: 0.239161
[27] valid_0's multi_logloss: 0.234454
[28] valid_0's multi_logloss: 0.229221
[29] valid_0's multi_logloss: 0.225168
[30] valid_0's multi_logloss: 0.220564
[31] valid_0's multi_logloss: 0.217413
[32] valid_0's multi_logloss: 0.213796
[33] valid_0's multi_logloss: 0.209798
[34] valid_0's multi_logloss: 0.206158
[35] valid_0's multi_logloss: 0.202923
[36] valid_0's multi_logloss: 0.200481
[37] valid_0's multi_logloss: 0.198662
[38] valid_0's multi_logloss: 0.196412
[39] valid_0's multi_logloss: 0.194417
[40] valid_0's multi_logloss: 0.192569
[41] valid_0's multi_logloss: 0.190719
[42] valid_0's multi_logloss: 0.189407
[43] valid_0's multi_logloss: 0.187703
[44] valid_0's multi_logloss: 0.186364
[45] valid_0's multi_logloss: 0.184915
[46] valid_0's multi_logloss: 0.183598
[47] valid_0's multi_logloss: 0.182639
[48] valid_0's multi_logloss: 0.181472
[49] valid_0's multi_logloss: 0.180405
[50] valid_0's multi_logloss: 0.179333
[51] valid_0's multi_logloss: 0.178182
[52] valid_0's multi_logloss: 0.17724
[53] valid_0's multi_logloss: 0.176375
[54] valid_0's multi_logloss: 0.175762
[55] valid_0's multi_logloss: 0.175282
[56] valid_0's multi_logloss: 0.174697
[57] valid_0's multi_logloss: 0.17415
[58] valid_0's multi_logloss: 0.173869
[59] valid_0's multi_logloss: 0.17318
[60] valid_0's multi_logloss: 0.172733
[61] valid_0's multi_logloss: 0.172024
[62] valid_0's multi_logloss: 0.171474
[63] valid_0's multi_logloss: 0.171093
[64] valid_0's multi_logloss: 0.170575
[65] valid_0's multi_logloss: 0.170069
[66] valid_0's multi_logloss: 0.169674
[67] valid_0's multi_logloss: 0.1692
[68] valid_0's multi_logloss: 0.168655
[69] valid_0's multi_logloss: 0.168365
[70] valid_0's multi_logloss: 0.167922
[71] valid_0's multi_logloss: 0.167672
[72] valid_0's multi_logloss: 0.167392
[73] valid_0's multi_logloss: 0.167152
[74] valid_0's multi_logloss: 0.166795
[75] valid_0's multi_logloss: 0.166484
[76] valid_0's multi_logloss: 0.166176
[77] valid_0's multi_logloss: 0.16586
[78] valid_0's multi_logloss: 0.165626
[79] valid_0's multi_logloss: 0.165419
[80] valid_0's multi_logloss: 0.165195
[81] valid_0's multi_logloss: 0.164999
[82] valid_0's multi_logloss: 0.16474
[83] valid_0's multi_logloss: 0.164555
[84] valid_0's multi_logloss: 0.164367
[85] valid_0's multi_logloss: 0.164149
[86] valid_0's multi_logloss: 0.164002
[87] valid_0's multi_logloss: 0.16386
[88] valid_0's multi_logloss: 0.163718
[89] valid_0's multi_logloss: 0.163589
[90] valid_0's multi_logloss: 0.163441
[91] valid_0's multi_logloss: 0.163278
[92] valid_0's multi_logloss: 0.163212
[93] valid_0's multi_logloss: 0.16311
[94] valid_0's multi_logloss: 0.163003
[95] valid_0's multi_logloss: 0.162931
[96] valid_0's multi_logloss: 0.162856
[97] valid_0's multi_logloss: 0.16273
[98] valid_0's multi_logloss: 0.162677
[99] valid_0's multi_logloss: 0.162568
[100] valid_0's multi_logloss: 0.162504
Did not meet early stopping. Best iteration is:
[100] valid_0's multi_logloss: 0.162504
training model for CV #5
[1] valid_0's multi_logloss: 0.888092
Training until validation scores don't improve for 10 rounds
[2] valid_0's multi_logloss: 0.807693
[3] valid_0's multi_logloss: 0.733491
[4] valid_0's multi_logloss: 0.671129
[5] valid_0's multi_logloss: 0.618705
[6] valid_0's multi_logloss: 0.57604
[7] valid_0's multi_logloss: 0.537409
[8] valid_0's multi_logloss: 0.505426
[9] valid_0's multi_logloss: 0.479669
[10] valid_0's multi_logloss: 0.450762
[11] valid_0's multi_logloss: 0.424318
[12] valid_0's multi_logloss: 0.401659
[13] valid_0's multi_logloss: 0.379624
[14] valid_0's multi_logloss: 0.360976
[15] valid_0's multi_logloss: 0.344415
[16] valid_0's multi_logloss: 0.330197
[17] valid_0's multi_logloss: 0.316947
[18] valid_0's multi_logloss: 0.304189
[19] valid_0's multi_logloss: 0.292354
[20] valid_0's multi_logloss: 0.282748
[21] valid_0's multi_logloss: 0.27266
[22] valid_0's multi_logloss: 0.264334
[23] valid_0's multi_logloss: 0.256925
[24] valid_0's multi_logloss: 0.250391
[25] valid_0's multi_logloss: 0.243777
[26] valid_0's multi_logloss: 0.238721
[27] valid_0's multi_logloss: 0.233946
[28] valid_0's multi_logloss: 0.228615
[29] valid_0's multi_logloss: 0.224572
[30] valid_0's multi_logloss: 0.219902
[31] valid_0's multi_logloss: 0.216819
[32] valid_0's multi_logloss: 0.21314
[33] valid_0's multi_logloss: 0.209137
[34] valid_0's multi_logloss: 0.205516
[35] valid_0's multi_logloss: 0.202264
[36] valid_0's multi_logloss: 0.19985
[37] valid_0's multi_logloss: 0.19802
[38] valid_0's multi_logloss: 0.195812
[39] valid_0's multi_logloss: 0.193766
[40] valid_0's multi_logloss: 0.191952
[41] valid_0's multi_logloss: 0.190067
[42] valid_0's multi_logloss: 0.188738
[43] valid_0's multi_logloss: 0.186915
[44] valid_0's multi_logloss: 0.18549
[45] valid_0's multi_logloss: 0.184087
[46] valid_0's multi_logloss: 0.182655
[47] valid_0's multi_logloss: 0.181576
[48] valid_0's multi_logloss: 0.180405
[49] valid_0's multi_logloss: 0.179379
[50] valid_0's multi_logloss: 0.178372
[51] valid_0's multi_logloss: 0.1772
[52] valid_0's multi_logloss: 0.17624
[53] valid_0's multi_logloss: 0.175243
[54] valid_0's multi_logloss: 0.174661
[55] valid_0's multi_logloss: 0.17419
[56] valid_0's multi_logloss: 0.173562
[57] valid_0's multi_logloss: 0.172985
[58] valid_0's multi_logloss: 0.172743
[59] valid_0's multi_logloss: 0.172077
[60] valid_0's multi_logloss: 0.171579
[61] valid_0's multi_logloss: 0.170879
[62] valid_0's multi_logloss: 0.170339
[63] valid_0's multi_logloss: 0.169927
[64] valid_0's multi_logloss: 0.169393
[65] valid_0's multi_logloss: 0.168907
[66] valid_0's multi_logloss: 0.168512
[67] valid_0's multi_logloss: 0.168046
[68] valid_0's multi_logloss: 0.167479
[69] valid_0's multi_logloss: 0.167142
[70] valid_0's multi_logloss: 0.166733
[71] valid_0's multi_logloss: 0.16642
[72] valid_0's multi_logloss: 0.166117
[73] valid_0's multi_logloss: 0.16594
[74] valid_0's multi_logloss: 0.165631
[75] valid_0's multi_logloss: 0.165319
[76] valid_0's multi_logloss: 0.165009
[77] valid_0's multi_logloss: 0.164692
[78] valid_0's multi_logloss: 0.164448
[79] valid_0's multi_logloss: 0.164204
[80] valid_0's multi_logloss: 0.164001
[81] valid_0's multi_logloss: 0.163816
[82] valid_0's multi_logloss: 0.16362
[83] valid_0's multi_logloss: 0.163419
[84] valid_0's multi_logloss: 0.163196
[85] valid_0's multi_logloss: 0.162951
[86] valid_0's multi_logloss: 0.162872
[87] valid_0's multi_logloss: 0.162699
[88] valid_0's multi_logloss: 0.162559
[89] valid_0's multi_logloss: 0.16243
[90] valid_0's multi_logloss: 0.162293
[91] valid_0's multi_logloss: 0.162156
[92] valid_0's multi_logloss: 0.162047
[93] valid_0's multi_logloss: 0.161981
[94] valid_0's multi_logloss: 0.161849
[95] valid_0's multi_logloss: 0.161724
[96] valid_0's multi_logloss: 0.161577
[97] valid_0's multi_logloss: 0.161448
[98] valid_0's multi_logloss: 0.161383
[99] valid_0's multi_logloss: 0.161339
[100] valid_0's multi_logloss: 0.16119
Did not meet early stopping. Best iteration is:
[100] valid_0's multi_logloss: 0.16119
print(f'{accuracy_score(y, np.argmax(p_val, axis=1)) * 100:.4f}%')
93.2466%
print(p_val.shape, p_tst.shape)
(320000, 3) (80000, 3)
np.savetxt(p_val_file, p_val, fmt='%.6f', delimiter=',')
np.savetxt(p_tst_file, p_tst, fmt='%.6f', delimiter=',')
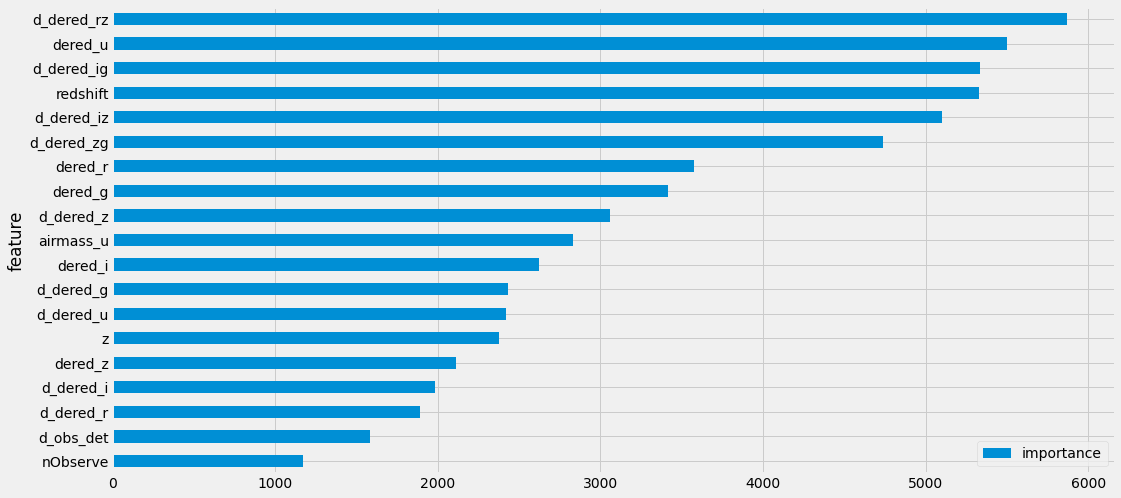
피처 중요도 시각화¶
imp = pd.DataFrame({'feature': df.columns, 'importance': clf.feature_importances_})
imp = imp.sort_values('importance').set_index('feature')
imp.plot(kind='barh')
<matplotlib.axes._subplots.AxesSubplot at 0x7ff2ac331150>
제출 파일 생성¶
sub = pd.read_csv(sample_file, index_col=0)
print(sub.shape)
sub.head()
(80000, 1)
| class | |
|---|---|
| id | |
| 320000 | 0 |
| 320001 | 0 |
| 320002 | 0 |
| 320003 | 0 |
| 320004 | 0 |
sub[target_col] = np.argmax(p_tst, axis=1)
sub.head()
| class | |
|---|---|
| id | |
| 320000 | 2 |
| 320001 | 0 |
| 320002 | 2 |
| 320003 | 0 |
| 320004 | 2 |
sub[target_col].value_counts()
2 41111
0 29973
1 8916
Name: class, dtype: int64
sub.to_csv(sub_file)