데모¶
라이브러리 import 및 설정¶
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from matplotlib import pyplot as plt
from matplotlib import rcParams
import numpy as np
from pathlib import Path
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
import seaborn as sns
import warnings
rcParams['figure.figsize'] = (16, 8)
plt.style.use('fivethirtyeight')
pd.set_option('max_columns', 100)
pd.set_option("display.precision", 4)
warnings.simplefilter('ignore')
학습데이터 로드¶
03-pandas-eda.ipynb에서 생성한 feature.csv 피처파일 사용
data_dir = Path('../data/dacon-dku')
feature_dir = Path('../build/feature')
val_dir = Path('../build/val')
tst_dir = Path('../build/tst')
sub_dir = Path('../build/sub')
trn_file = data_dir / 'train.csv'
tst_file = data_dir / 'test.csv'
sample_file = data_dir / 'sample_submission.csv'
target_col = 'class'
n_fold = 5
n_class = 3
seed = 42
model_names = ['lrcv_polyfeature', 'rfcv_feature', 'lgbcv_feature']
algo_name = 'lrcv'
feature_name = 'stacking1'
model_name = f'{algo_name}_{feature_name}'
feature_file = feature_dir / f'{feature_name}.csv'
p_val_file = val_dir / f'{model_name}.val.csv'
p_tst_file = tst_dir / f'{model_name}.tst.csv'
sub_file = sub_dir / f'{model_name}.csv'
Stacking Feature 생성¶
trn = []
tst = []
for model in model_names:
trn.append(np.loadtxt(val_dir / f'{model}.val.csv', delimiter=','))
tst.append(np.loadtxt(tst_dir / f'{model}.tst.csv', delimiter=','))
trn = np.hstack(trn)
tst = np.hstack(tst)
print(trn.shape, tst.shape)
(320000, 9) (80000, 9)
feature_names = []
for model in model_names:
feature_names += [f'{model}_class0', f'{model}_class1', f'{model}_class2']
feature_names
['lrcv_polyfeature_class0',
'lrcv_polyfeature_class1',
'lrcv_polyfeature_class2',
'rfcv_feature_class0',
'rfcv_feature_class1',
'rfcv_feature_class2',
'lgbcv_feature_class0',
'lgbcv_feature_class1',
'lgbcv_feature_class2']
y = pd.read_csv(trn_file, index_col=0, usecols=['id', target_col]).values.flatten()
y.shape
(320000,)
Stratified K-Fold Cross Validation¶
cv = StratifiedKFold(n_splits=n_fold, shuffle=True, random_state=seed)
Logistic Regression 모델 학습¶
p_val = np.zeros((trn.shape[0], n_class))
p_tst = np.zeros((tst.shape[0], n_class))
for i, (i_trn, i_val) in enumerate(cv.split(trn, y), 1):
print(f'training model for CV #{i}')
clf = LogisticRegression(multi_class='multinomial')
clf.fit(trn[i_trn], y[i_trn])
p_val[i_val, :] = clf.predict_proba(trn[i_val])
p_tst += clf.predict_proba(tst) / n_fold
training model for CV #1
training model for CV #2
training model for CV #3
training model for CV #4
training model for CV #5
print(f'{accuracy_score(y, np.argmax(p_val, axis=1)) * 100:.4f}%')
93.0947%
print(p_val.shape, p_tst.shape)
(320000, 3) (80000, 3)
np.savetxt(p_val_file, p_val, fmt='%.6f', delimiter=',')
np.savetxt(p_tst_file, p_tst, fmt='%.6f', delimiter=',')
피처 중요도 시각화¶
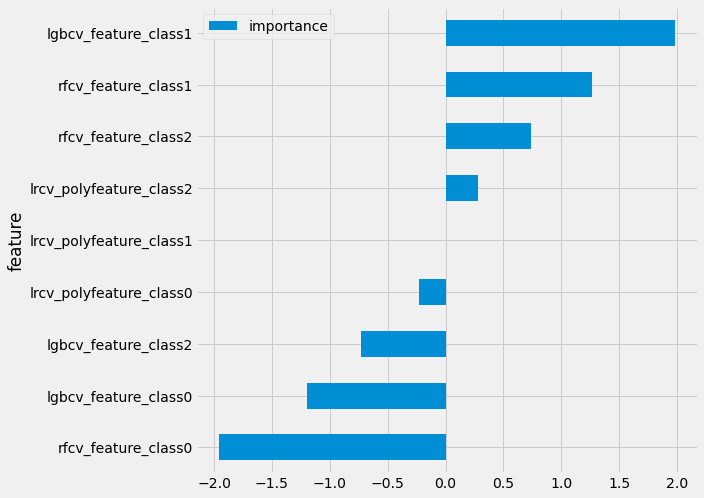
clf.coef_.shape
(3, 9)
imp = pd.DataFrame({'feature': feature_names, 'importance': clf.coef_[1, :].T})
imp = imp.sort_values('importance').set_index('feature')
imp.plot(kind='barh', figsize=(8, 8))
<matplotlib.axes._subplots.AxesSubplot at 0x7fd4899b7e10>
제출 파일 생성¶
sub = pd.read_csv(sample_file, index_col=0)
print(sub.shape)
sub.head()
(80000, 1)
| class | |
|---|---|
| id | |
| 320000 | 0 |
| 320001 | 0 |
| 320002 | 0 |
| 320003 | 0 |
| 320004 | 0 |
sub[target_col] = np.argmax(p_tst, axis=1)
sub.head()
| class | |
|---|---|
| id | |
| 320000 | 2 |
| 320001 | 0 |
| 320002 | 2 |
| 320003 | 0 |
| 320004 | 2 |
sub[target_col].value_counts()
2 41194
0 29968
1 8838
Name: class, dtype: int64
sub.to_csv(sub_file)