3. Pandas¶
데이터과학을 할 때 가장 많이 사용하는 언어가 파이썬과 R입니다. 2010년도에 데이터과학이 유명해지기 시작할 때만 해도 R에서 제공하던 함수 및 라이브러리가 파이썬보다 더 많았습니다. R에서 사용하던 여러가지 기능들을 파이썬에서 제공하기 시작한게 Pandas 라이브러리 부터라고 볼 수 있습니다. 그래서 파이썬에서 데이터과학을 하는데 Pandas는 필수적인 라이브러리입니다.

그림 3-1 Pandas 로고(출처)

그림 3-2 Wes McKinney(출처)
Pandas는 2008년에 Wes McKinney의 개인 프로젝트로 시작했습니다. Wes는 미국 동부에서 금융업에 종사하면서 파이썬을 활용해 금융 데이터 분석을 하고 있었습니다. R에서는 그 당시 여러가지 기능들을 제공 했지만 느리다는 단점이 있었고, 파이썬은 R보다는 빠르지만 다양한 기능을 제공하는 오픈 소스 라이브러리가 없었습니다. 그래서 본인이 사용하기 위해서 개인 프로젝트로 Pandas를 만들기 시작했습니다. Pandas에 기능이 하나 둘씩 추가되면서 다른 사람들도 많이 사용하기 시작했으며 본인 회사 내에서 먼저 유명하게 됐습니다. 그리고 나서 회사를 설득해서 Pandas를 오픈 소스로 출시하게 됩니다. 지금은 Pandas를 쓰지 않는 데이터 과학자가 없다고 해도 무방할 정도로 많은 사람이 사용하는 라이브러리가 됐습니다.
금융쪽에서는 테이블 형태의 정형데이터를 패널 데이터(panel data)라고 칭합니다. Panel data를 줄여서 Pandas로 이름을 지었다고 하다가, 후일담으로 판다가 귀엽기 때문에 그냥 Pandas라고 했다라는 얘기를 하기도 했습니다. Pandas가 지원하는 기능으로는 데이터 입출력, 변환, 선택, 결합, 전처리, 그룹핑 등이 있습니다.
3.1 Pandas 설치¶
Pandas는 Anaconda Navigator 또는 터미널을 통해 설치할 수 있습니다. Anaconda Navigator로 설치하는 방법은 Environments 탭에 가서 설치를 원하는 가상환경을 선택 후 Pandas 라이브러리 옆에 체크 박스를 선택하면 설치가 됩니다.

그림 3-3 Anaconda Navigator에서 Pandas 설치(출처)
터미널을 통해서 설치하는 방법은 먼저 터미널에서 Pandas를 설치할려고 하는 가상환경을 conda activate [가상환경 이름] 명령어를 통해 실행 후 pip install pandas를 통해 설치 가능합니다. 라이브러리를 사용하다가 새 버전이 나와서 업그레이드를 해야 한다면 터미널에서 pip install -U pandas명령어를 통해 업그레이드 할 수 있습니다. 해당 명령어는 기존에 pandas가 없는 경우 pandas를 최신 버전으로 설치해주며 pandas가 있는 경우에는 최신 버전으로 업그레이드 해줍니다.
Note
pip은 파이썬에서 사용하는 패키지 관리 프로그램입니다. pip을 통해 다양한 라이브러리를 다운로드 받고 관리할 수 있습니다.
3.2 Pandas 객체¶
Pandas에서는 데이터프레임과 시리즈라는 객체를 지원합니다. 데이터프레임은 R에서 넘어온 개념이며 테이블 형식으로 된 데이터를 뜻합니다. 반면 시리즈는 1차원적인 벡터 형식으로 된 데이터를 뜻합니다. 예를 들어 그림 3-4는 인덱스가 있고 두 개의 열이 있습니다. 첫번째 열은 u라는 열이고 두번째 열은 g라는 열입니다. 또한 첫번째 행은 count라는 행이며 두번째 행은 mean이라는 행입니다. 이처럼 2차원적인 데이터를 저장할 때 Pandas에서는 데이터프레임이라는 객체를 사용합니다.
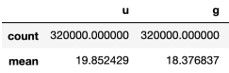
그림 3-4 데이터프레임 예시(출처)
데이터프레임에서 하나의 컬럼만 뽑아낸다면 그것은 1차원 데이터가 될 것이며 이것을 시리즈라고 합니다. 시리즈는 인덱스 값이 원소 값과 같이 저장됩니다. 인덱스는 별도로 명시하지 않으면 0부터 시작을 합니다. 그림 3-5에 dtype이라고 하는 것은 데이터 타입을 뜻합니다. 데이터 타입은 정수형, 실수형, 시간형, 문자열 등이 있는데 3.3절에서 자세히 다뤄보도록 하겠습니다.

그림 3-5 시리즈 예시(출처)
Pandas 객체는 여러개의 member function을 보유하고 있습니다. 예를 들어 df라는 데이터프레임이 존재할 때 df.head() 함수를 사용하면 데이터프레임의 상위 5개의 행을 출력해줍니다. 주요 member function들에 대한 설명은 아래와 같으며 실습 단계에서 자세히 다뤄 보겠습니다.
함수 |
설명 |
|---|---|
|
데이터프레임 또는 시리즈의 상위, 하위 5개의 행을 출력합니다. |
|
행 또는 열을 선택할 때 사용합니다. |
|
행/열에 특정 함수를 적용할 때 사용합니다. |
|
특정 열로 그룹핑을 할 때 사용합니다. |
|
특정 열 또는 인덱스의 값으로 정렬할 때 사용합니다. |
|
행/열을 삭제할 때 사용합니다. |
|
행과 열의 크기를 반환합니다. |
|
특정 행/열에 몇 개의 값이 존재하는지 계산합니다. |
|
특정 행/열의 총 합을 반환합니다. |
|
누적 합을 반환합니다. |
|
평균값을 반환합니다. |
|
중앙값을 반환합니다. |
|
최솟값을 반환합니다. |
|
최댓값을 반환합니다. |
|
표준편차를 반환합니다. |
|
분산을 반환합니다. |
|
특정 개수 또는 퍼센트 만큼의 표본을 추출해서 반환합니다. |
|
해당 열에 존재하는 고유값을 반환합니다. |
|
해당 열에 존재하는 고유값의 개수를 반환합니다. |
|
각 고유값별 개수를 반환합니다. |
|
인덱스를 새로 지정할 때 사용합니다. |
|
인덱스를 초기화 시키고 기존 인덱스를 컬럼으로 변환하고자 할 때 사용합니다. |
표 3-1 Pandas 객체의 주요 member function
3.3 Pandas 데이터 타입¶
Pandas에서 제공하는 주요 데이터 타입은 아래와 같습니다.
데이터 타입 |
설명 |
|---|---|
Int64, float64 |
64비트 정수/실수 |
bool |
True/False |
object |
문자열 포함 임의의 데이터 타입 |
datetime64[ns] |
날짜/시간 |
timedelta64[ns] |
날짜/시간 차이 |
|
데이터 타입 변환 시 사용 |
|
문자를 날짜/시간으로 변환 |
표 3-2 Pandas에서 제공하는 주요 데이터 타입
또한 Pandas에는 NaN 데이터 타입이 존재하는데 Not a Number의 약자로써 결측값을 뜻합니다. NaN을 처리하는 주요 함수는 아래와 같습니다.
함수 |
설명 |
|---|---|
|
NaN이 있는지 여부 확인 (T/F) |
|
NaN이 있는 행/열 삭제 |
|
NaN이 있는 행/열 대치 |
표 3-3 NaN을 처리하는 주요 함수
3.4 Pandas 함수¶
이 외에도 주로 사용 되는 함수는 아래와 같습니다.
함수 |
설명 |
|---|---|
|
CSV 파일 입출력 |
|
서로 다른 DataFrame 결합 |
|
데이터 히스토그램/시각화 |
dt.day/weekday/month/year/weekofyear |
Datetime[ns] 타입 데이터의 일/요일/월/년/주 |
|
Datetime[ns] 타입 데이터 리샘플링 |
|
피봇테이블 생성 |
|
상관관계 계산 |
표 3-4 Pandas의 주요 함수
3.5 Jupyter Notebook 실행 및 확장팩 설치¶
Pandas 실습을 하기 위해 Jupyter Notebook을 먼저 실행하겠습니다. Jupyter Notebook을 실행하는 방법은 2.2.4절을 참고 바랍니다.
Jupyter Notebook에는 다양한 확장팩을 지원하는데, 확장팩을 설치하는 방법은 터미널에서 conda install -c conda-forge jupyter_contrib_nbextensions를 입력하면 됩니다.
확장팩 설치가 완료되면 Jupyter Notebook 메인 화면에 Nbextensions 탭이 추가됩니다. 해당 탭에 들어가서 사용하고자 하는 확장팩을 설정할 수 있습니다.

그림 3-6 Nbextensions
여러 개의 확장팩 중에서 주로 사용하게 되는 확장팩은 ExecuteTime과 Table of Contents입니다. ExecuteTime은 각 셀별로 실행 시간을 표출해주며 Table of Contents는 마크다운 문법에 기반해서 목차를 생성해줍니다.
지금까지 Pandas에 대한 이론적인 배경과 Jupyter Notebook 확장팩에 대해 배워봤습니다. 다음 장에서는 Pandas 실습을 진행해보도록 하겠습니다.
3.6 참고자료¶
파이썬 라이브러리를 활용한 데이터 분석 2판은 Pandas 창시자인 Wes McKinney가 집필한 책이므로 Pandas에 활용법에 대해 자세히 나와 있습니다. 그 외에도 캐글에서 제공하는 Pandas 강좌나 Pandas 공식 홈페이지 문서를 필요 시 참고하시길 바랍니다.