6. Scikit-learn (sklearn)¶
Scikit-learn 라이브러리는 파이썬의 대표적인 머신러닝 라이브러리 입니다. 2007년에 교토 대학에서 박사과정을 하고 있던 David Cournapeau가 Google Summer of Code 프로젝트로 시작하게 됐습니다.
Note
Google Summer of Code는 더 많은 학생 개발자를 오픈 소스 소프트웨어 개발에 참여시키는 데 초점을 맞춘 글로벌 프로그램입니다. 10주 프로그래밍 프로젝트에서 오픈 소스 조직과 협력합니다.: https://summerofcode.withgoogle.com/

그림 6-1 Scikit-learn 로고(출처)
그 당시에는 머신러닝 연구를 하거나 개발을 해야 되면 Matlab같은 유료 프로그램을 사용했야 했습니다. 그래서 파이썬으로 무료로 사용할 수 있는 머신러닝 라이브러리를 만드는 것을 2007년에 David이 개인 프로젝트로 시작했습니다.
2010년에는 프랑스의 국가연구소인 INRIA에서 운영권을 넘겨 받아 v0.1을 공개했습니다. 그 이후로는 매 분기마다 새로운 버전을 공개해 2020년 8월에는 v0.23.2를 공개했습니다.
Scikit-learn은 다양한 머신러닝 알고리즘과 데이터 전처리 기능, 모델 평가 지표 등 머신러닝 알고리즘을 사용하는데 필요한 여러 기능을 구현한 라이브러리 입니다. 또한 앞서 배운 pandas, numpy, 그리고 matplotlib 라이브러리들과 호환이 잘 됩니다. 그래서 파이썬으로 머신러닝 프로젝트를 하게 된다면 pandas와 numpy와 더불어 가장 많이 사용되는 라이브러리 입니다.
6.1 ML 알고리즘¶
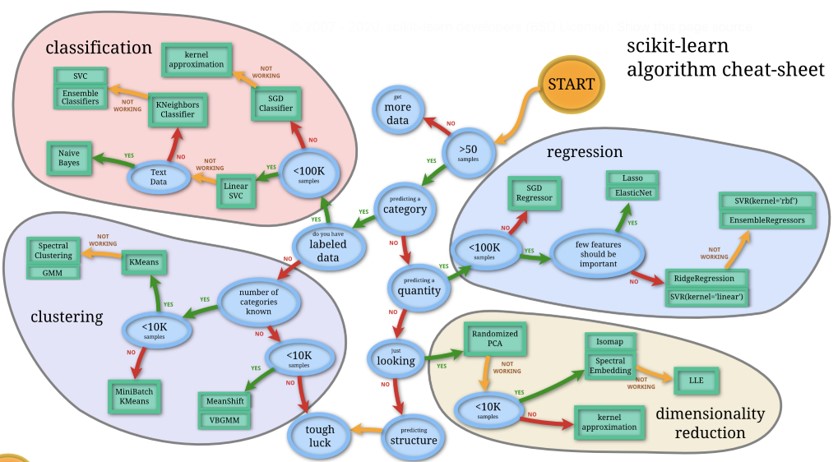
그림 6-2 Machine learning map(출처)
그림 6-2는 Scikit-learn 공식 홈페이지에서 제공하는 머신러닝 알고리즘 사용 가이드입니다. 가장 처음에 샘플의 개수를 확인 후 50개 이하면 데이터를 더 수집하고 50개 이상이면은 다음 단계로 진행 합니다. 그리고 나서 종속변수가 범주형인지 아닌지를 확인 하고, 라벨링이 되어 있는지 아닌지 등을 확인하면서 각 상황별 적합한 알고리즘을 추천해주는 가이드라인입니다.
해당 그림을 참고해 Scikit-learn에서 제공하는 알고리즘을 정리하자면 분류 할 때 사용하는 classification 알고리즘, 연속형 변수를 예측하는 regression 알고리즘, 비지도학습의 일종인 clustering 알고리즘, 그리고 변수 변환을 지원하는 dimensionality reduction 알고리즘이 있습니다.
앞서 4장에서 단국대 소/중 데이터를 활용해 regression 알고리즘인 선형회귀와 classification 알고리즘인 로지스틱회귀를 적용해봤습니다. 아래 그림을 통해 알고리즘 사용 방법을 다시 복습해보겠습니다.

그림 6-3 LinearRegression 사용 예제(출처)
Regression 알고리즘을 학습할 때는 fit()함수를 사용하고, 독립변수와 종속변수를 입력 값으로 주어 학습을 진행합니다. 예측할 때는 predict()함수를 사용해 주어진 입력값에 대한 예측을 진행합니다.

그림 6-4 LogisticRegression 사용 예제(출처)
Classification 알고리즘을 학습할 때도 fit()함수를 사용합니다. 예측할 때는 predict()을 사용해 범주를 곧바로 예측할 수도 있으며 predict_proba()를 사용해 각 범주에 속할 확률을 예측할 수도 있습니다. N개의 샘플에 대해 2개의 범주에 속할 확률을 각각 예측하게 되면 predict_proba()의 결과물은 N행 2열의 행렬이 반환됩니다. 그래서 특정 범주 하나에만 속할 확률을 알고 싶을 때는 인덱싱을 통해 특정 열을 선택해줘야 합니다. 그림 6-4에서는 [:, 1] 인덱싱을 통해 범주 1에 속할 확률을 추출했습니다.

그림 6-5 Clustering 사용 예제(출처)
그림 6-5은 clustering 알고리즘을 사용하는 예제입니다. 비지도학습 알고리즘이기 때문에 종속변수인 y는 없습니다. 그래서 X만 fit()함수에 입력값으로 주어 학습을 진행합니다. 마찬가지로 예측을 할 때는 predict()함수를 사용합니다.

그림 6-6 Scikit-learn의 주요 알고리즘(출처)
그림 6-6에는 scikit-learn에서 주로 사용하는 알고리즘을 나타냅니다. 선형 모델로는 LinearRegression이나 LogisticRegression 알고리즘을 주요 사용합니다. 트리 기반 모델로는 DecisionTreeRegressor과 DecisionTreeClassifier를 사용합니다. 데이터과학 대회에서 주로 사용되는 알고리즘은 sklearn.ensemble모듈에서 제공하는 RandomForestRegressor, RandomForestClassifier, GradientBoostingRegressor, 그리고 GradientBoostingClassifier가 되겠습니다.
6.2 변수 변환¶
Scikit-learn에서 제공하는 주요 변수 변환 기능을 확인해보겠습니다.
함수 |
설명 |
|---|---|
MinMaxScaler |
최댓값과 최솟값을 1과 0으로 변환 |
StandardScaler |
정규분포로 변환 |
RobustScaler |
이상치의 영향을 덜 받는 변환 방법 |
QuantileTransformer |
백분위수 정보를 활용해 변환 |
PowerTransformer |
yeo-johnson 또는 box-cox 방법으로 정규분포화 하는 방법 |
표 6-1 수치형 변수에 적용 가능한 변환 방법
함수 |
설명 |
|---|---|
LabelEncoder |
0 부터 N까지의 숫자로 각 범주를 변환, 종속변수에 사용 |
OneHotEncoder |
각 범주를 이진 변수로 변환해 0과 1로만 범주를 표현 |
OrdinalEncoder |
0 부터 N까지의 숫자로 각 범주를 변환, 독립변수에 사용 |
표 6-2 범주형 변수에 적용 가능한 변환 방법
함수 |
설명 |
|---|---|
PCA |
차원 축소 알고리즘 |
표 6-3 차원 축소 시 사용하는 비지도 알고리즘
ML 알고리즘 함수는 fit()과 predict()명령어를 사용한 반면 변수 변환 함수는 fit()과 transform()함수를 사용합니다. fit_transform()처럼 두 개의 기능을 합친 함수도 지원합니다.

그림 6-7 변수 변환 API 사용 예제(출처)
Scikit-learn에서는 텍스트 데이터를 숫자로 변환하는 함수도 제공합니다. 대표적으로 CountVectorizer와 TfidfVectorizer가 존재합니다. CountVectorizer는 입력 텍스트에 있는 모든 단어들을 개별 변수로 보고 각 단어의 등장 횟수를 세어 수치화합니다. 아래 그림과 같습니다.

그림 6-8 CountVectorizer 사용 예제(출처)
corpus에 등장한 모든 단어를 변수로 확인한 뒤 ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']의 변수 리스트를 생성합니다. corpus의 첫번째 문장인 This is the first document.에 있는 단어들의 개수를 세어 [0, 1, 1, 1, 0, 0, 1, 0, 1]로 수치화 된것을 확인할 수 있습니다.
TfidfVectorizer는 term frequency와 inverse document frequency 값을 곱해서 수치화 하는 방법입니다. Term frequency는 해당 문서내 특정 단어가 출몰한 빈도수를 뜻하며 앞서 CountVectorizer가 계산한 값을 뜻합니다. Inverse document frequency는 한 단어가 전체 문서에서 등장한 횟수를 역수 취한 값입니다. Inverse document frequency를 term frequency에 곱해주는 이유는 전체 문서에 자주 등장하는 단어인 경우 단어의 중요도를 낮추고, 특정 문서에만 자주 등장하는 단어인 경우 중요도를 높이기 위함입니다. 아래와 같이 sklearn.feature_extraction.text모듈에서 불러올 수 있습니다.

그림 6-9 TfidfVectorizer 사용 예제(출처)
Note
TfidfVectorizer는 자연어처리에서 기본이 되는 변수 변환 방법입니다. 최근에는 딥러닝 방법의 강세로 인해 자주 사용되지는 않지만 기본적인 분석이나 모델링을 할 때 종종 사용됩니다.
6.3 평가 지표 (Metric)¶
Scikit-learn에서는 모델 평가를 위한 다양한 평가 지표를 제공합니다. 분류 문제에서 자주 사용되는 log_loss, roc_auc_score, accuracy_score, confusion_matrix가 사용됩니다. 아래는 confusion_matrix를 사용한 예시입니다.

그림 6-10 confusion_matrix 사용 예제(출처)
confusion_matrix에서 우하향하는 대각선에 있는 숫자는 모델이 정답을 맞춘 개수를 뜻합니다. 예를 들어 0행 0열에 있는 원소값은 실제값이 0인 샘플 중 모델이 119,705개를 0으로 맞췄다는 뜻입니다. 그 외의 위치에 있는 숫자들은 예측 모델이 틀린 개수를 뜻하며, 어떻게 예측을 해서 틀린 것인지 확인할 수 있습니다. 예를 들어 1행 2열에 있는 13,333은 실제값이 1인 샘플 13,333개를 모델이 2로 예측해서 틀렸다는 것을 알 수 있습니다. Confusion matrix를 통해 모델이 1과 2인 클래스를 헷갈려 하는 것을 확인할 수 있습니다.
회귀 문제에서 자주 사용되는 평가 지표는 mean_squared_error, mean_absolute_error, 그리고 r2_score이며 각각 sklearn.metrics모듈에서 불러올 수 있습니다.

그림 6-11 회귀 모델 평가지표 사용 예제(출처)
6.4 검증 (Validation)¶
Scikit-learn에서는 모델 검증을 진행할 때도 유용한 함수들을 제공합니다. 가장 많이 사용되는 함수들은 train_test_split, KFold, 그리고 StratifiedKFold입니다.
train_test_split은 학습 데이터셋의 일부를 나누어, 예를 들어 60%는 학습시 사용하고 40%는 검증시 사용하고자 할 때 사용합니다. 아래와 같이 코드로 구현 가능합니다.

그림 6-12 train_test_split 사용 예제(출처)
train_test_split함수의 test_size인자에는 검증 데이터로 사용하고자 하는 비율을 입력하고 random_state인자에는 임의의 정수를 입력해 데이터를 분리하기전 셔플링하는 과정이 재현될 수 있도록 합니다.
Tip
데이터과학 대회에 팀 단위로 참여시 팀원 간의 실험 재현이 될 수 있도록 random_state를 고정해두는 것이 필요합니다.
KFold는 학습 데이터를 K개로 분리해서 교차검증을 할 때 사용합니다. 그림 6-13 처럼 5개의 fold로 나눌 시 각 fold에서 사용하는 test 데이터셋은 모델 학습시 사용하지 않은 데이터가 됩니다. 교차 검증은 전체 학습 데이터에 대한 모델 성능 검증이 가능합니다.
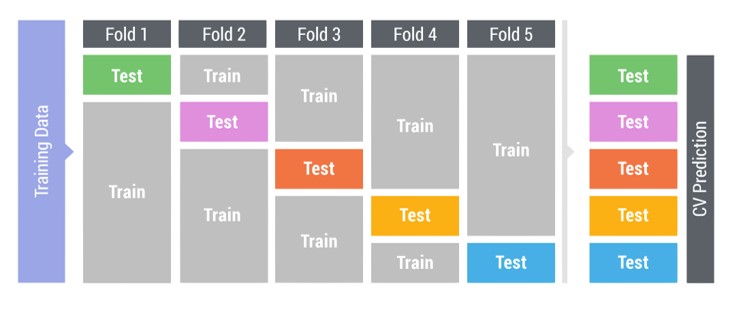
그림 6-13 5-fold Cross-Validation(출처)
Tip
KFold는 모든 데이터셋을 활용해 검증을 하기 때문에 train_test_split보다 과적합을 방지하는데 효과적입니다.
KFold사용 예제는 아래와 같습니다.
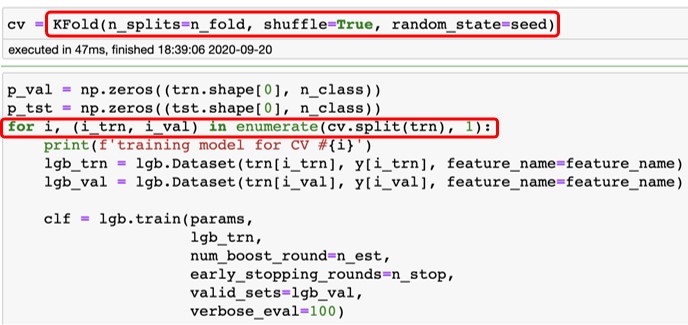
그림 6-14 KFold 사용 예제(출처)
shuffle과 random_state인자를 설정합니다. KFold 실습은 8장에서 진행해보겠습니다.
6.5 결정트리¶
Scikit-learn에서 제공하는 알고리즘 중 결정트리(Decision Trees)에 대해 알아보겠습니다. 결정트리는 7장에서 학습할 Random Forest와 LightGBM의 기반에 되기 때문에 먼저 학습해보겠습니다.
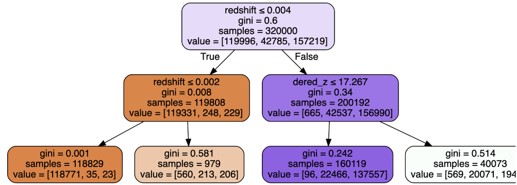
그림 6-15 시각화된 결정트리(출처)
결정트리는 일련의 결정 규칙에 기반한 예측모델입니다. 위 그림에서 나온 것 처럼 처음에는 redshift가 0.0004보다 작거나 같은지 확인을 하고 그 다음 단계에서 또 각각의 규칙을 적용합니다. 가장 아래에 있는 단말 노드에 도달하게 되면 하나의 범주를 예측하게 됩니다.
결정트리의 특징으로는 분류 문제와 회귀 문제 모두 적용가능하며 모델 해석에 용이합니다. 그림 6-15 처럼 시각화를 통해 어떤 규칙을 사용했는지 확인할 수 있습니다. 또한 스케일에 영향을 받지 않습니다. 스케일이 달라도 동일한 결과가 나오므로 데이터 전처리시 스케일링을 적용하지 않아도 무관합니다. 또한 범주형변수를 수치형변수로 변환하지 않아도 학습이 가능한 알고리즘입니다.
결정트리를 분류 모델로 학습하는 방법과 회귀 모델로 학습하는 방법이 있는데, 두 가지의 학습 방법 모두 특정 노드에서 손실함수를 최소화 하는 변수와 기준값을 탐색합니다. 그리고 선정된 변수와 기준값으로 자식 노드를 생성하고 특정 조건이 만족할 때 까지 이 과정을 반복합니다. 분류 모델에서는 Gini 또는 Entropy로 손실함수를 정의하며 회귀 모델에서는 MSE 또는 MAE를 손실함수를 정합니다.
Scikit-learn에서 결정트리를 학습하는 예시는 아래와 같습니다.

그림 6-16 결정트리 학습 예제(출처)
graphvis 라이브러리를 활용해 결정트리를 시각화 할 수 있으며 예시 코드는 그림 6-16에 있습니다.