1. Intro¶
캐글(Kaggle)은 대표적인 데이터과학 경진대회 플랫폼입니다. 본 강좌를 통해 데이터과학을 자세히 배워보고 데이터과학에 입문하는 계기가 됐으면 합니다. 1장에서는 본 과목에 대한 소개와 더불어 데이터과학 대회에 대해 전반적으로 알아보겠습니다.
1.1 과목 소개¶
2012년에 하버드 비즈니스 리뷰에서 21세기 가장 섹시한 직종을 데이터 사이언티스트라고 발표했습니다. 그래서 그만큼 많은 사람들이 관심을 가지고 있고, 회사에서도 데이터 과학자를 뽑기 위해서 많은 노력을 하고 있는 상황입니다.

그림 1-1 2012년 하버드 비즈니스 리뷰 표지 (출처)
데이터 사이언티스트가 가장 핫한 직종이라고 하고 그만큼 수요도 많이 있지만, 막상 데이터과학에 신입으로 입문하기는 상대적으로 굉장히 어렵습니다. 데이터과학이 융합 학문이기 때문에 다양한 기술을 요구하고, 요구되는 다양한 기술을 모두 숙달 하기가 쉽지 않기 때문에 입문하기가 상대적으로 어렵습니다. 데이터과학은 전산학, 통계학, 그리고 분야 전문성(Domain Experty)이라는 세가지가 접목돼 이뤄진 학문입니다. 그래서 전산학에서 사용되는 기술도 배워야 되고, 통계에서 사용되는 기술도 배워야 되고, 또 각각의 도메인 내에서 사용되는 내용들도 배워야 하는 어려움이 있습니다. 학부 과정을 통해 이 세가지중 하나만 학습하기도 어려운데, 세가지를 동시에 학습을 해야 하기 때문에 어떻게 보면 학부생 또는 신입들이 접근하기 굉장히 어려운 학문입니다.

그림 1-2 데이터 사이언티스트 벤 다이어그램 (출처)
그럼에도 불구하고 데이터과학에 관심이 있어서 접근하고자 한다면, 캐글과 같은 데이터과학 대회를 통해 접근하는것이 가장 효율적이라고 생각합니다. 그래서 본 강좌에서는 데이터과학에 필요한 각종 알고리즘과 분석 기법 그리고 소프트웨어에 대해서 학습할 예정이며, 학습한 내용을 대회에 직접 적용해 보는 시간을 갖겠습니다. 이렇게 대회에 직접 적용을 해봄으로써 데이터과학에 입문 하실 수 있는 기초를 마련해 드리고자 합니다.
본 강좌에서는 머신러닝 알고리즘에 대한 상세한 이론적인 개념과 프로그래밍 입문 내용은 다루지 않을 예정입니다.
1.2 데이터과학 대회¶
1.2절에서는 데이터과학 대회 전반에 대해 소개드리도록 하겠습니다. 대회 참여를 권하는 이유, 왜 지금이 참여하기 적절한 시기인지, 데이터과학 대회 사례, 데이터과학 대회의 역사, 그리고 대회 형식에 대해 알아보겠습니다.
1.2.1 왜 참여하는가?¶
데이터과학 대회 참여를 권하는 이유는 4가지가 있습니다. 첫번째는 재미있기 때문입니다. 많은 분들께서 게임 또는 스포츠를 직접 하거나 관람하는 것을 좋아하실 겁니다. 게임이나 스포츠를 즐겨하는 이유는 다른 사람들과 경쟁하는게 재미있기 때문일 것입니다. 또는 해당 게임 내에서 본인의 실력이 향상되는것 자체가 즐겁기 때문일 것입니다. 그런 것과 마찬가지로 데이터과학 대회에 참여함으로써 다른 사람들과 경쟁도 하고 협동도 할 수 있으며, 동시에 본인의 실력이 향상되는 것도 경험할 수가 있습니다. 가장 매력적인 부분은 본인의 실력이 향상 됐을때 본인의 경력과 진로에 직접적인 도움이 된다는 것입니다. 게임에서 본인 실력 향상은 본인의 경력과 진로에 직접적인 도움이 되지 않을 수 있지만, 데이터과학 대회에서는 본인의 성적이 올라갈 수록 본인 경력에 직접적인 도움이 됩니다. 데이터과학 대회에 참여하면 재미도 있고 경력에 도움도 되는 1석 2조의 효과가 있어 대회 참여를 권합니다.
두번째 이유는 배움을 위해서 참여를 권장드립니다. 1.1절에서 언급한 것처럼 데이터과학은 여러 학문이 융합된 학문이다 보니 배워야 할게 너무 많아 전문성을 가지기가 상당히 어렵습니다. 데이터과학 대회에 참가를 한다면 정말 다양한 데이터와 데이터과학 문제들을 직접 접하면서 배울 수 있는 아주 좋은 기회를 제공해 줍니다. 또한 어떤 데이터에는 어떤 알고리즘을 적용해야 하는 것을 학교 수업을 통해서 배우기가 쉽지 않은데, 여러 대회에 참가를 해보면 그것이 직접 몸으로 체감이 되고 다른 사용자들이 공유하는 코드를 통해서 데이터와 알고리즘의 적합성에 대해 쉽게 배울 수 있는 기회가 제공됩니다. 또한 데이터과학에서는 알고리즘만 중요한 게 아니라 데이터를 어떤식으로 처리하고 분석하고 마지막으로 알고리즘을 적용하는 전반적인 접근 방식이 중요합니다. 이러한 접근 방식에 대해서 가르쳐 줄 수 있는 환경이 그렇게 많지가 않습니다. 회사에 가도 전반적인 접근 방식은 직접 일을 하면서 배울 수 있는 것이라서 수업에서 배우기가 쉽지 않습니다. 하지만 데이터과학 대회에 참가를 하면 정말 다양한 접근 방식을 비교적 짧은 기간 내 많이 배울 수 있습니다. 그러므로 데이터과학 이라는 복잡한 학문을 배우기에 가장 적합한 환경을 제공해 주는것이 데이터과학 대회라고 볼 수 있습니다.
세번째 이유는 전 세계의 데이터 과학자들과 교류 할 수 있는 계기가 될 수 있기 때문에 참여를 권장드립니다. 그림 1-3에서 가장 우측에는 남미 출신으로 캐글에서 가장 좋은 성적을 거둔 Gilberto Titericz라는 데이터 과학자이고, 우측에서 두번째는 인도 출신으로 캐글에서 가장 높은 랭크에 올라간 Abhishek Thakur라는 데이터 과학자이고, 마지막으로 좌측에서 두번째는 그리스 출신으로 유럽에서 가장 높은 랭크에 있는 Marios Michailidis라는 데이터 과학자입니다. 이처럼 전 세계에 있는 뛰어난 데이터 과학자들과 이제 친분을 쌓고 교류를 할 수 있는 기회가 될 수 있습니다.

그림 1-3 전 세계의 데이터 과학자들 (출처)
마지막으로 대회 참여가 궁긍적으로 본인의 경력 개발에 큰 도움을 주기 때문에 권장드립니다. 회사에 입사를 하거나 이직을 할 시에 본인의 출신 학교 또는 과거에 다닌 직장보다, 대회에서 우승을 하거나 좋은 성적을 거둔 기록이 더 도움이 될 수 있습니다. 그렇기 때문에 나중에 데이터 과학자로 취직을 희망하시는 분들께서는 경력 개발을 위해 데이터 과학 대회에 참여 하시는 것을 적극 추천드립니다.
1.2.2 왜 참여하기 적절한 시기인가?¶
데이터과학 대회에 참여를 권하는 다른 이유 중 하나는 지금이 바로 대회에 참가하기 가장 좋은 시기이기 때문입니다. 불과 10년 전만 해도 머신러닝 백그라운드가 없는 일반인이 데이터과학 대회에 참가를 해서 데이터과학에 입문 한다는게 굉장히 어려웠습니다. 그런데 지금은 상황이 많이 달라져서 머신러닝 또는 통계학적인 백그라운드가 없다고 하더라도 데이터과학 대회를 통해 데이터 과학에 입문하기 굉장히 좋은 상황이 됐습니다. 적절한 시기가 온 것에는 6가지 이유가 있습니다.
첫번째로 각종 다양한 데이터셋이 많이 공개돼 있습니다. 예를 들어 예전에는 의료 데이터 분석하는 것을 배우고 싶을 때, 의료 데이터를 구하는게 쉽지 않았습니다. 병원에 취직을 하거나 의료 회사에 취직을 해야만 의료 데이터에 접근할 수가 있었는데, 지금은 손쉽게 데이터 대회 플랫폼에 가서 검색만 하면 각종 의료 데이터에 접근할 수가 있습니다.
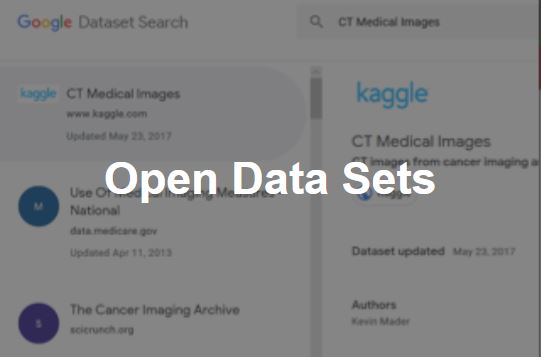
그림 1-4 공개된 데이터셋 (출처)
두번째는 최신 연구결과에 대한 정보에 누구든 접근할 수 있기 때문입니다. 예전에는 데이터과학의 최신 내용을 배우기 위해 해당 학회에 참가를 해서 다른 과학자들이 발표하는 내용을 접해야 최신 연구들에 대해 배우고 적용할 수 있었습니다. 지금은 각종 학회에 논문을 제출하기 전에 arxiv.org라고 하는 온라인 사이트에 먼저 논문을 공개한 후 학회에 제출하는 식으로 트렌드가 바꼈습니다. 그래서 이제 최신 논문들을 온라인 인터넷 상에서 누구나 무료로 최신 논문들을 볼 수 있게 됐습니다. 그래서 데이터과학에 입문하기 굉장히 좋은 시기입니다.

그림 1-5 arxiv.org에 공개된 논문 (출처)
세번째로는 오픈 소스 코드가 다 공개돼 있기 때문입니다. 예전에는 최신 연구 결과가 논문으로 나왔다 하더라도 논문에 나온 연구 결과를 직접 코드로 모두 구현했어야 했습니다. 요즘은 논문을 구현한 코드를 저자가 오픈 소스로 Github에 공개하는게 트렌드입니다. 그래서 머신러닝 분야의 가장 최신 연구 결과들은 해당 코드를 Github에 가면 얼마든지 다운로드해서 실행해볼 수 있습니다. 연구 결과도 무료로 접근할 수 있고, 그것에 대한 코드도 무료로 다운로드 받을 수 있는 상황입니다.

그림 1-6 Github에 공개된 소스코드 (출처)
네번째로는 오픈 소스 소프트웨어가 일반화됐기 때문입니다. 예전에는 데이터과학 대회에 참가하는 사람들이 자기가 사용할 알고리즘을 직접 구현해서 참가해야 했습니다. 그래서 대회에서 수상하는 사람들은 최신 알고리즘을 잘 구현할 수 있는 사람들이 였습니다. 요즘은 가장 최신 알고리즘들이 오픈 소스로 공개돼 있습니다. 그래서 Tensorflow, PyTorch, scikit-learn, xgboost, 그리고 lightgbm 이런 것들이 전부 오픈 소스 소프트웨어로 누구나 인터넷에서 다운로드 받아 자신의 컴퓨터에 설치를 할 수 있습니다. 그래서 해당 알고리즘을 데이터셋에 적용해서 누구나 괜찮은 성능의 모델을 구축해볼 수 있는 소프트웨어들이 다 공개돼 있습니다.

그림 1-7 각종 오픈소스 라이브러리 (출처)
다섯번째로는 일반인이 접근할 수 있는 하드웨어 가격이 굉장히 떨어졌고 성능이 좋아졌습니다. 예전에는 슈퍼컴퓨터 또는 굉장히 성능이 좋은 서버를 가지고 있는 대학 아니면 구글, 페이스북과 같은 유수 회사에 일하는 사람들만 큰 모델들과 최신 모델들을 돌릴 수 있었습니다. 요즘은 100만원 정도, 또는 50만원에서 60만원 정도의 Nvidia GPU 그래픽 카드를 설치하면 웬만한 최신 연구 결과 성과를 내는 알고리즘 및 소프트웨어들을 직접 실행시켜볼 수 있습니다. 그래서 컴퓨터를 자신이 조립해서 유수 대기업 또는 대학 연구소와 경쟁 해보는게 가능해졌습니다.

그림 1-8 저렴하면서도 성능이 좋은 하드웨어 (출처)
마지막으로는 클라우드 플랫폼의 등장입니다. 클라우드 플랫폼 덕분에 100만원 정도의 컴퓨터를 조립할 예산이 없어도 대기업과 경쟁할 수 있는 시대가 왔습니다. Amazon AWS, Microsoft Azure, Google Cloud Platform과 같은 클라우드 플랫폼을 활용해 사용한 시간만큼 시간당 1만원, 2만원씩 내면서 최상의 하드웨어를 얼마든지 빌려 사용할 수 있습니다. 실제로 어떤 알고리즘 대회에서 구글과 경쟁해서 구글을 이긴 팀이 있었는데, 해당 팀은 자체 하드웨어를 쓴게 아니라 Amazon AWS에서 4만원 정도를 지불해 서버를 빌려서 구글을 경쟁에서 이겼습니다. 즉, 누구나 구글이나 페이스북 같은 대기업 또는 MIT, 스탠포드와 같은 우수 대학 연구소와 경쟁 할 수 있는 시기가 왔습니다. 그래서 꼭 대기업만 데이터과학 대회에서 좋은 성능을 내고 수상할 수 있는 시기가 아니라 일반인들도 오픈 데이터 오픈 소스 소프트웨어, 클라우드 플랫폼을 잘 활용하기만 한다면 대기업 못지 않은 성과를 낼 수 있는 시대입니다.

그림 1-9 주요 클라우드 플랫폼 (출처)
그래서 지금이 데이터과학에 입문하기 가장 좋은 시기고, 데이터과학 대회에 참여하기 가장 좋은 시기라고 볼 수 있습니다. 여러분도 이번 기회에 데이터과학 대회에 모두 입문해 보시길 바랍니다.
1.2.3 데이터과학 대회 사례¶
오픈소스 및 공개된 최신 연구결과를 활용한 여러 데이터과학 대회 사례를 이번 절에서 확인해보겠습니다. 첫번째 사례는 마이크로소프트의 Imagine Cup입니다. 2018년도 Imagine Cup에서 우승한 팀이 스마트 팔(Smart Arm)이라는 제품을 개발해서 우승을 했습니다. 해당 제품은 머신러닝과 클라우드 플랫폼, 3d 프린터 등의 기술을 융합해서 구축한 솔루션입니다. 해당 제품은 3d 프린터로 만든 의수라고 볼 수 있는데, 의수 가운데에 카메라가 있어 어떤 물건을 집을 때 어느 정도의 힘을 사용해야 하는지를 머신 러닝 알고리즘으로 계산하고, 계산한 힘을 가해서 물건을 집어 줍니다.

그림 1-10 Microsoft Imagine Cup (출처)
두번째 사례는 안과 질환을 예측하는 어플리케이션(Eyeagnosis) 입니다. 그림 1-11에 있는 고등학생은 스탠포드에서 나온 논문을 온라인으로 접하고, 인공지능 모델을 이용해서 안과 질환을 예측하는 논문을 보게 됐습니다. 그래서 논문에 나온 기술을 활용한 안과 질환을 진단하는 아이폰 앱을 개발하게 됐습니다. 또한 진단을 위해선 눈에 강한 빛을 쏴줘야 하는데, 3d 프린터를 활용한 돋보기를 구축해서, 아이폰의 플래쉬를 더 강하게 만들어 눈에 쏘고, 아이폰 카마라를 활용해 이미지를 찍어 진단을 하는 방식을 구축했습니다. 이 사례에서도 3d 프린터와 아이폰 앱과 더불어 공개된 논문과 오픈소스인 텐서플로우를 활용해 혁신적인 솔루션을 고등학생이 개발할 수 있었습니다.

그림 1-11 Eyeagnosis을 개발한 학생 (출처)
세번째 사례는 클라우드 플랫폼을 활용해 4명의 소규모 집단이 구글을 이긴 사례입니다. (참고1, 참고2) 해당 대회는 약 130만개의 이미지를 1000개의 종류로 분류하는 대회였는데, 가장 빠르게 특정 성능을 웃도는 모델을 만드는 것이 목표였습니다. 그래서 구글이 자체 서버를 활용해 30분만에 해당 과업을 달성했습니다. 이런 구글 팀을 4명으로 구성된 소규모 팀이 AWS에서 40불 정도의 GPU 자원을 활용해 알고리즘을 학습해서 18분만에 특정 성능을 웃도는 과업을 달성해서 구글을 이겼습니다. 구글이 학습한 시간의 60% 밖에 안되는 시간내에 알고리즘을 학습 시킨 것입니다.

그림 1-12 구글을 이긴 소규모 집단에 대한 기사 (출처)
마지막 사례는 Mikel Bober-Irizar 학생입니다. 해당 학생은 14살에 컴퓨터를 조립하던 아르바이트를 했습니다. 고등학교 때 비디오카드를 포함한 컴퓨터를 조립해주고 했는데, 자신한테 컴퓨터를 주문하는 사람들이 보니까 캐글이라는 머신러닝 대회에 참가 하는 것을 알게 됐습니다. 그래서 자기도 자연스레 관심을 갖게 되어 대회 참가를 시작하게 됐습니다. 그 당시 Mikel은 통계 및 머신러닝에 대한 배경이 전혀 없었습니다. 하지만 캐글 대회에 참여한지 3년 만에 플랫폼에서 가장 높은 등급인 컴피티션 그랜드마스터를 달성했습니다. 또한 구글에서 주최한 Google Landmark Retrieval Challenge에서도 1등을 해서 CVPR 학회에 초대를 받아 하와이에서 본인의 솔루션을 공개하고, 이런 업적들을 인정 받아 대학도 옥스포드에 있는 대학에도 입학 허가를 받았습니다.

그림 1-13 Mikel Bober-Irizar 캐글 프로필 (출처)
결론적으로, 대학생이 혁신적인 제품을 만들기도 하고, 고등학생이 뛰어난 의료 솔루션을 개발하기도 하고, 대기업이 아니더라도 구글보다 뛰어난 솔루션을 개발 할 수도 있는 시대가 현재 도래했다고 볼 수 있습니다. 공개된 자원들을 어떻게 활용하느냐에 따라서 이처럼 의미있는 일들을 누구나 할 수 있습니다.
1.2.4 데이터과학 대회 역사¶
1.2.4절에서는 데이터과학 대회의 역사에 대해 소개해보겠습니다. 1997년에 지금과 같은 데이터과학 대회가 처음으로 개최됐는데, 그 당시에는 데이터과학 쪽의 가장 유명한 국제학회인 kdd에서 매년 여는 정규 대회로 시작됐습니다. 데이터과학 대회가 많이 알려지게 된 계기는 2006년에서 2009년 사이에 있었던 Netflix Grand Prize 라는 대회 때문이였습니다. 2006년에 있던 넷플릭스 대회는 그 당시 정말 파격적이었던 12억원 정도의 상금을 가지고 개최가 됐습니다. 그 당시 목표가 Netflix의 추천 알고리즘의 성능을 10% 이상 향상시킨 팀에게 백만달러 상금을 지급하는 목표를 가지고 개최된 대회였습니다. 무려 5만 팀이 넘는 팀이 참가를 하였고 3년 동안 추천 시스템 분야에 많은 기여를 한 대회로 아직도 회자되고 있습니다. 이 대회를 통해 정말 많은 사람들이 대회에 참가를 하기도 했고, 일반인에게 많이 알려지게 된 계기가 되었습니다. 그래서 2009년에 대회 종료 후 상금이 수여되고 바로 그 이듬해에 캐글이 시작됐습니다. 캐글은 현재 전 세계에서 가장 큰 데이터가 과학 플랫폼이며 전 세계의 500만명이 넘는 사람들이 캐글 플랫폼에서 대회를 참가하고 있습니다.

그림 1-14 데이터과학 경진대회 역사 (출처)
한국에서는 2018년 8월에 시작된 데이콘이 가장 큰 플랫폼 입니다. 많은 한국 데이터 경진대회가 데이콘 플랫폼에서 현재 개최되고 있습니다. 캐글은 말씀 드린 것처럼 500만명이 넘는 회원을 보유하고 있고, 현재까지 2,000개 이상의 대회가 개최 되었고, 지금까지 지불한 총 상금 액수는 1,200만 달러가 넘어갑니다. 큰 규모의 대회는 백만 달러가 넘어가는 대회도 있었고, 보통은 3만 달러에서 5만 달러 사이의 상금을 걸고 대회가 개최됩니다.
그림 1-15는 2010년부터 현재까지 일어난 각종 대회를 나타낸 차트입니다. y축은 참가 팀의 개수를 보여주고, 원의 크기는 총 상금의 크기를 보여주고 있습니다. 2010년부터 지금까지 대회 개수도 늘어나고 참가 팀수도 늘어나고, 상금 액수도 전반적으로 증가하고 있는 것을 확인할 수 있습니다.

그림 1-15 캐글에서 개최한 대회 정보 (출처)
그림 1-16는 다소 오래 전에 공개된 통계 자료입니다. 전 세계적으로 캐글 탑 랭커들의 분포를 정리한 차트입니다. 미국이 압도적으로 많고 그 다음에 러시아, 인도, 중국, 프랑스, 독일순이며 일본도 많은 랭커를 보유하고 있습니다. 한국은 지금은 이 숫자보다 훨씬 많은 랭커분들이 계십니다. 이 자료는 1, 2년된 정도된 자료이며, 그 당시에는 한국 랭커분들이 몇 분 안계셨습니다.

그림 1-16 국가별 캐글 탑 랭커 분포 (출처)
한국에서 대표적인 데이터과학 대회 플랫폼인 데이콘은 현재까지 18,000팀이 이상이 참가했고, 30개가 넘는 대회가 개최가 되었습니다. 그리고 1억 5천만원 이상의 상금이 현재까지 지급 됐습니다. 현재도 여러 대회가 개최중입니다.
1.2.5 데이터과학 대회 - 형식¶
이번 절에서는 데이터과학 대회의 형식을 살펴보겠습니다. 일반적으로 대회 기간에는 학습 데이터 세트의 feature와 label 값이 제공되며, 시험 데이터 세트는 feature만 제공되고 label은 제공 되지 않습니다. 그래서 대회기간에는 시험 데이터 세트에 대한 label을 예측을 해서 제출해야 합니다. 예측 값을 제출하면 공개 리더보드에는 시험 데이터 세트의 일부에 대한 정답을 가지고 성적을 공개합니다. 대회가 끝나면 시험 데이터 세트의 나머지 데이터를 가지고 점수를 매겨서 해당 점수로 최종 순위를 결정합니다. 그래서 대회 중에 자신의 팀이 상위에 랭크가 돼있더라도 실제 최종 순위는 변경될 수 있습니다. 그러므로 대회 기간 동안에 눈에 보이지 않는 비공개 리더보드에 최적화된 솔루션을 제출하는것이 대회의 목표라고 볼 수 있습니다.
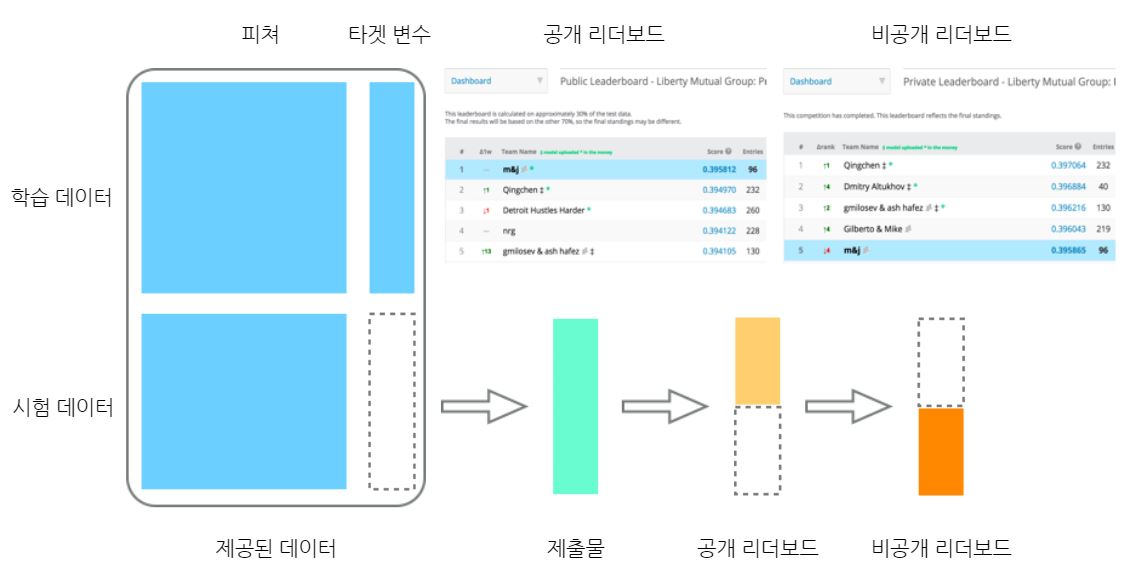
그림 1-17 데이터과학 대회 출제 형식 (출처)
1.3 참고자료¶
이상으로 대회에 대한 소개를 마무리하고, 본 강의와 함께 참고자료로 사용하면 좋은 자료들에 대해 소개드리겠습니다.
1.3.1 책¶
첫번째로 파이썬 라이브러리를 활용한 데이터분석 책입니다. 본 강의에서는 파이썬을 활용해 데이터 분석을 진행할 텐데, 이 때 필수적으로 필요한 라이브러리가 Pandas입니다. 파이썬 라이브러리를 활용한 데이터분석 책에선 Pandas 활용법을 소개하고 있습니다. 두번째 참고자료는 핸즈온 머신러닝 2판입니다. 해당 책에선 파이썬으로 머신러닝 알고리즘을 어떤 식으로 사용할 수 있는지, 그리고 각종 오픈소스 머신러닝 라이브러리에 대해 소개를 해주고 있는 책입니다. 세번째 책은 Approaching (Almost) Any Machine Learning Problem 책인데, 한글 번역본의 제목은 머신러닝 마스터 클래스입니다. 이 책의 저자가 바로 1.2.1절에서 소개했던 인도에서 캐글 랭크가 가장 높은 Abhishek Thakur입니다. Abhishek은 대회 성적 뿐만 아니라 각종 자료를 잘 만들기로도 유명한 그랜드마스터 입니다. 그래서 이 책에는 실전에서 활용할 수 있는 굉장히 다양한 코드와 분석 기법 및 머신러닝 기법에 대해 소개하고 있기 때문에 참고하시면 좋은 자료가 될 수 있겠습니다.

그림 1-18 강의와 함께 보면 좋은 참고문헌 (출처)
정리하자면, Pandas 라이브러리에 대해 더 알아보고자 하시면 파이썬 라이브러리를 활용한 데이터 분석 책을, 머신러닝 라이브러리를 배우고자 하시면 핸즈온 머신러닝 2판을, 그리고 대회기법을 확인하고자 하시면 Approaching (Almost) Any Machine Learning 책을 참고하시면 도움 되겠습니다.
1.3.2 온라인¶
그 외에도 온라인에도 여러가지 자료가 있습니다. 캐글 웹사이트에 있는 Kaggle Courses에 데이터과학 입문을 위한 여러 자료들이 있습니다. 또한 페이스북에 캐글 코리아라는 페이스북 그룹이 있습니다. 해당 그룹은 각종 대회에 대한 소식이나 자신이 배운 내용에 대해 활발하게 공유하는 그룹입니다. 또한 유튜브에 한국 캐글러로 유명하신 이유한 박사님의 채널에 많은 자료들이 공유가 돼있습니다. 여러 대회에 대한 팁과 강좌가 공유돼 있으니 확인하시면 도움 되겠습니다.
그림 1-19 온라인에 공개된 각종 자료 (출처)